漫画最开始的时候,孙悟空一个人待在水帘洞里,他不知道自己在等谁,也不知道等了多久,唐三藏走进水帘洞说,是你呼唤我么?孙悟空说我没有呼唤谁啊。唐三藏沉默了很久说,那你跟我走吧。然后他拉了孙悟空的手,孙悟空就跟他走了。在那个故事里,唐三藏是个使左轮枪的大帅哥而孙悟空是个傻猴子。这个世界上有很多种猴子,有的猴子被唐三藏从水帘洞里领出来之后,就变成聪明猴子了,翻着跟头就跑掉了,而有的猴子就只会跟着唐三藏走。我就是后面那种猴子,我在水帘洞里待的太久了,待傻了。
全文约1.6W字,大致阅读完约15分钟,包含主要知识点:CMS概述与识别的意义、根据页面内容识别CMS类型、根据请求头内容识别CMS类型、根据robots.txt文件识别CMS类型、根据网站文件md5值识别CMS类型、根据指定网页内容识别CMS类型、Python识别CMS代码工程设计实现与拓展、其中关键部位文字使用橙色重点标注,网址使用绿色重点标注,代码以及相关指纹库下载链接在文末。
目录:
CMS概述与识别的意义
根据页面内容识别CMS类型
根据请求头内容识别CMS类型
根据robots.txt文件识别CMS类型
根据网站文件md5值识别CMS类型
根据指定网页内容识别CMS类型
Python识别CMS代码工程设计实现与拓展
指纹库获取
附言:
最近相关开发文章都需要具有一定的python基础,但是许多朋友没有接触学习过,所以许多地方会觉得这讲的什么鸟玩意儿,其实这种情况是我很不想的。后面时间主要应用于视频课程的录制,从最基础的开始教学到后面完整的开发课程,一步一步的学习前进。其中也有一些个人原因,由于没有录制的经验,会经常笑场导致录制失败….
CMS概述与识别的意义
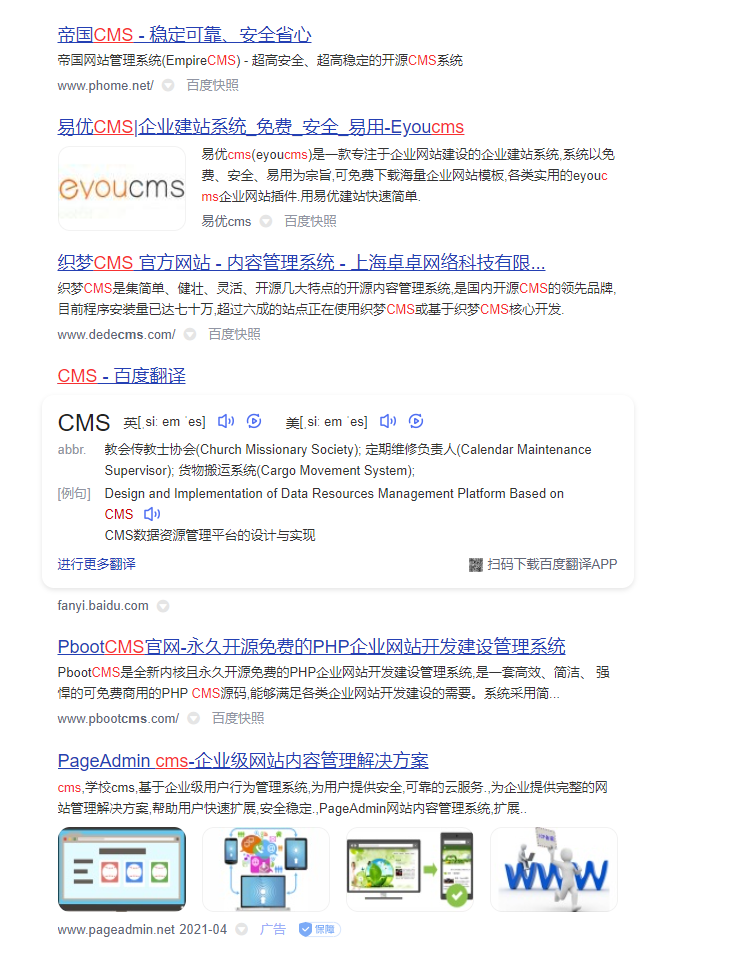
CMS是Content Management System的缩写,意为”内容管理系统”。可以简单理解为网站的模板,从零开始开发一个完整的网站系统需要大量的时间和人力成本,如果使用现成的模板套用则能节约大量的开发成本和人力资源。因此网络上有大量优秀的CMS模板提供选择使用:
优点:
- 节约开发成本,人力资源
- 快速上线整个网站系统
- 自带多样优秀丰富的插件功能,后台管理系统,提供不同风格的界面
- 简单易上手,能快速搭建网站
缺点:
- 安全性较低,因为使用的统一的模板,如果爆出该相关漏洞,那么你的网站也很可能被入侵
- 使用不当可能会造成版权问题
- 使用模板的话,网站的结构重复度太高,不利于搜索引擎优化
回归到本文的主旨,在渗透测试中检测目标网址是否基于CMS模板开发,判断使用的CMS类型是非常重要的一步,可以查找网上已曝光的CMS程序漏洞,运气好能一步到位拿到权限,如果该CMS系统开源,还能下载相对应的源码进行代码审计。
根据个人经验,总结一下识别网站CMS类型的五种方法,本质上都是根据网页内容或者网页文件的特征进行识别。只是根据不同类型的网页大概分成五类,方便理解和阅读,至于在网上找到在线识别CMS网站的接口然后加到爬虫中,省时省力却不在本文的讨论范围之内,当然会在以后视频课程的爬虫专栏会专门讲。
根据页面内容识别CMS类型
许多CMS系统会在网站的首页加上一些象征该CMS的关键词,举个例子,WordPress是一种使用PHP语言开发的博客平台,用户可以在支持PHP和MySQL数据库的服务器上架设自己的网站,如果使用该程序搭建网站,会在该网站的首页出现关键词
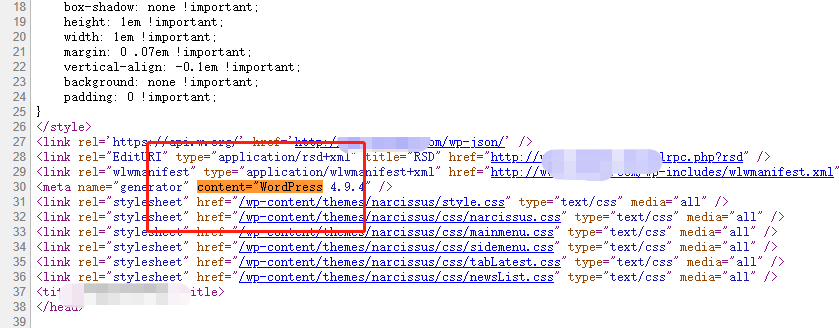
网站的开发人员如果不是闲着无聊加上wordpress这种词的话,那我们就能策略判断该网址是使用WordPress系统搭建的,这样我们识别出来后,就继续确认该网站使用Wordpress的版本号,然后搜索该版本是否出现过相关漏洞,进一步测试。
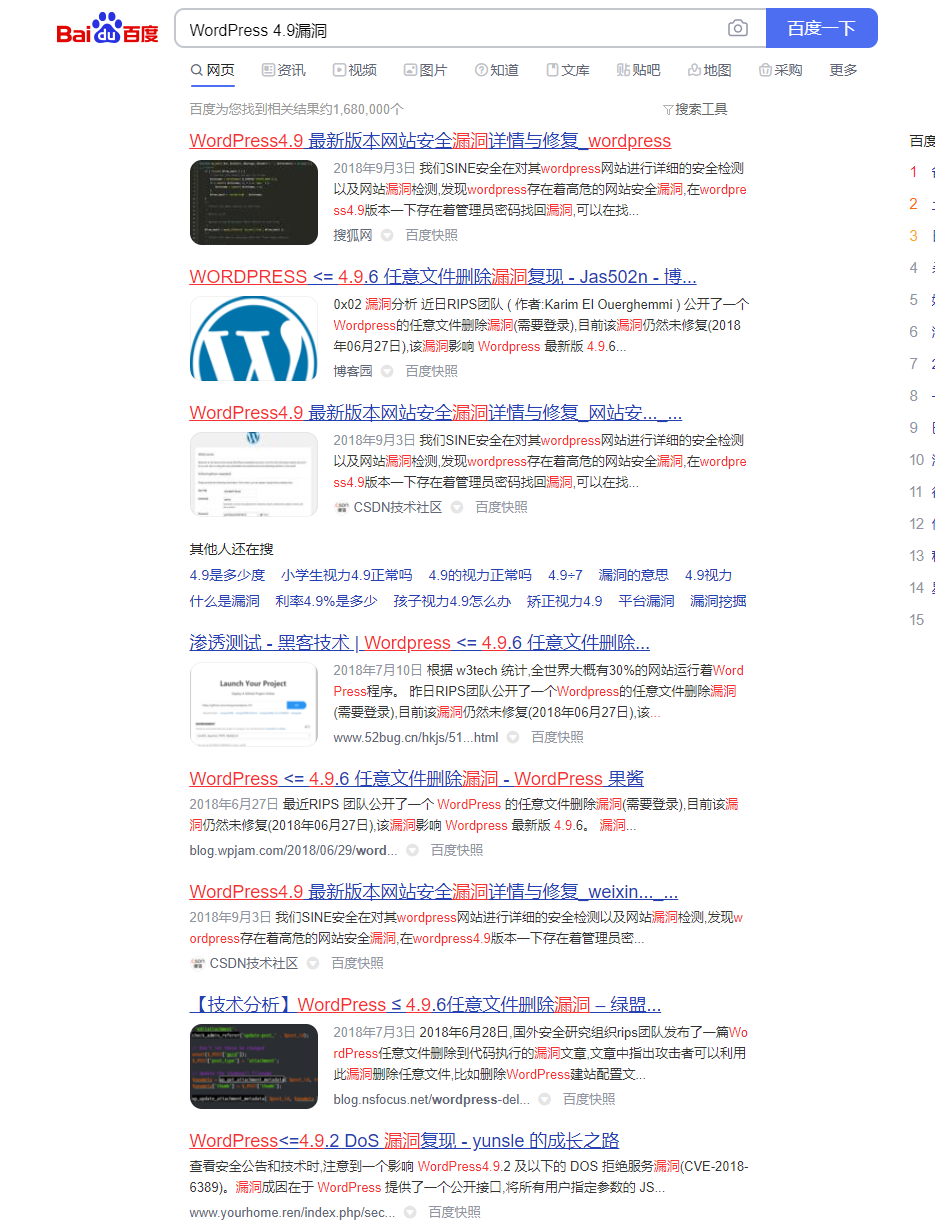
那么只需要准备一个指纹库,然后访问目标网站后,对照指纹库的内容,如果命中关键词,则直接判断该网址的CMS类型。
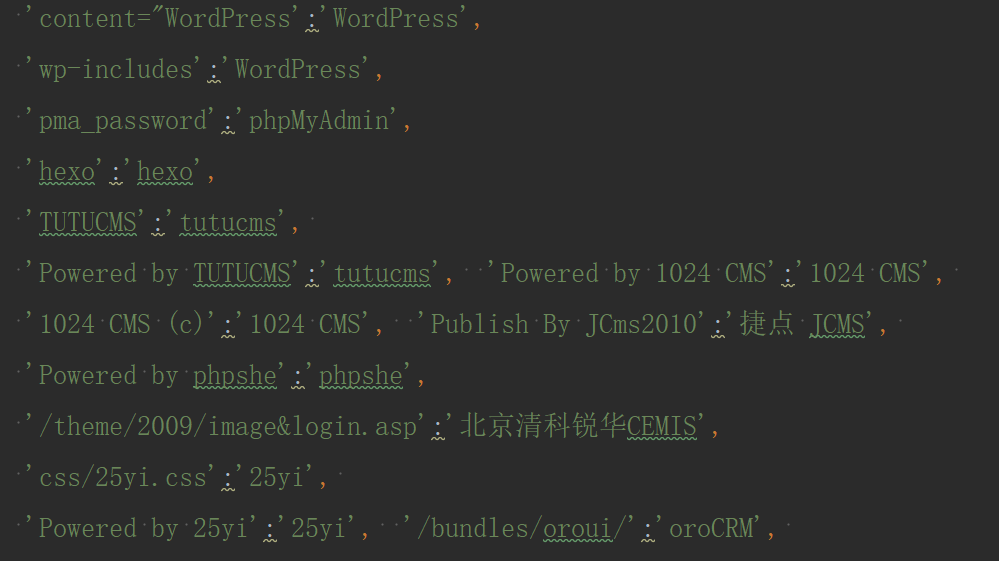
指纹库文件需要不断地收集更新整理,本文中整理好的指纹库获取方式放在文末自取,数据可能有些落后。
如果使用代码实现,粗略的大体结构大概就是如下设计:
# -*- coding:utf-8 -*-
import requests
body = {
'content="WordPress':'WordPress',
'wp-includes':'WordPress',
'pma_password':'phpMyAdmin',
'hexo':'hexo',
}
def CheckCmsFromBody(url):
try:
r = requests.get(url)
encoding = requests.utils.get_encodings_from_content(r.text)[0]
url_content = r.content.decode(encoding, 'replace')
for k,v in body.items():
if k in url_content:
print('目标网址:{} 识别CMS为:{}'.format(url,v))
except Exception as e:
print(e)
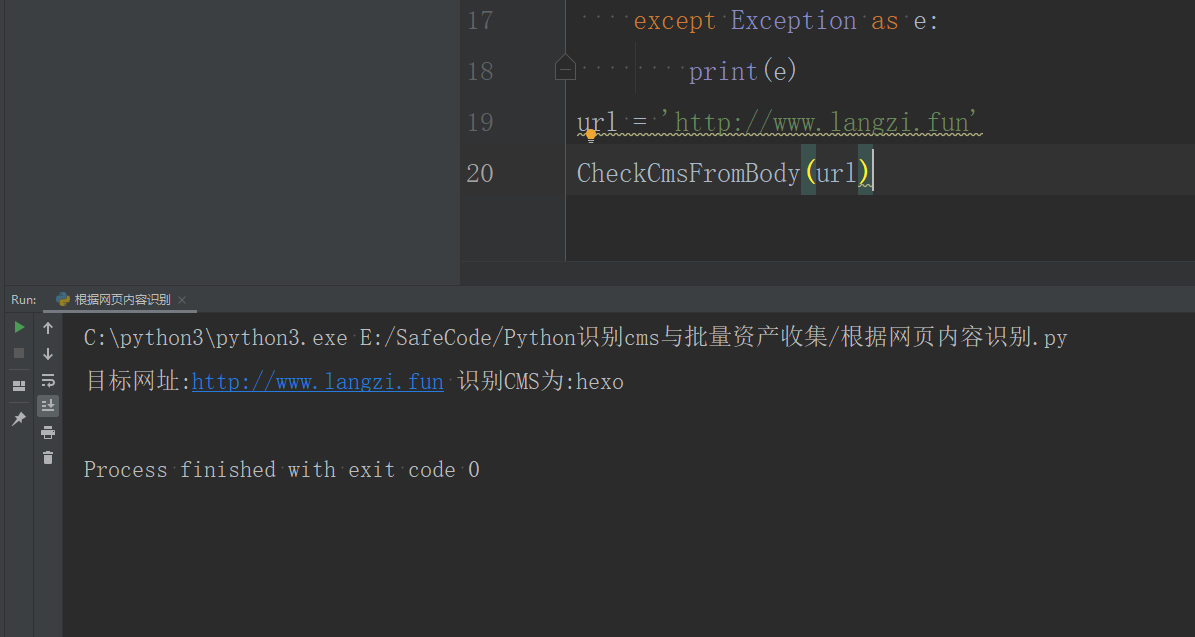
url = 'http://www.langzi.fun'
CheckCmsFromBody(url)
粗略就是获取首页的内容,然后从指纹库寻找是否出现关键词判定
根据请求头内容识别CMS类型
除了上文中从网页内容识别CMS类型,还可以从请求头消息中获取相关信息,某些CMS系统返回的请求头信息中也会添加独特的特征码。如下图目标网站就是使用PowerEasy(动易系统)搭建的网站,可以直接从请求头中获取到特征码,从而判断出使用CMS的类型。
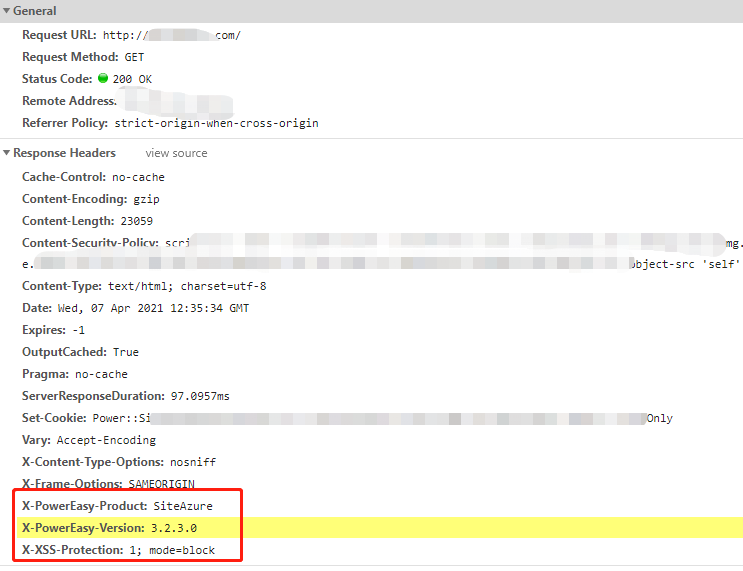
所以在渗透测试的信息收集中,对任何地方都不要放过呀~细心谨慎才能挖到更多的信息。
这个使用代码实现太简单了,会的同学都懒得看,没有基础的同学看了也看不懂…就不写了…
主要难点还是在于请求头指纹库的收集与更新。
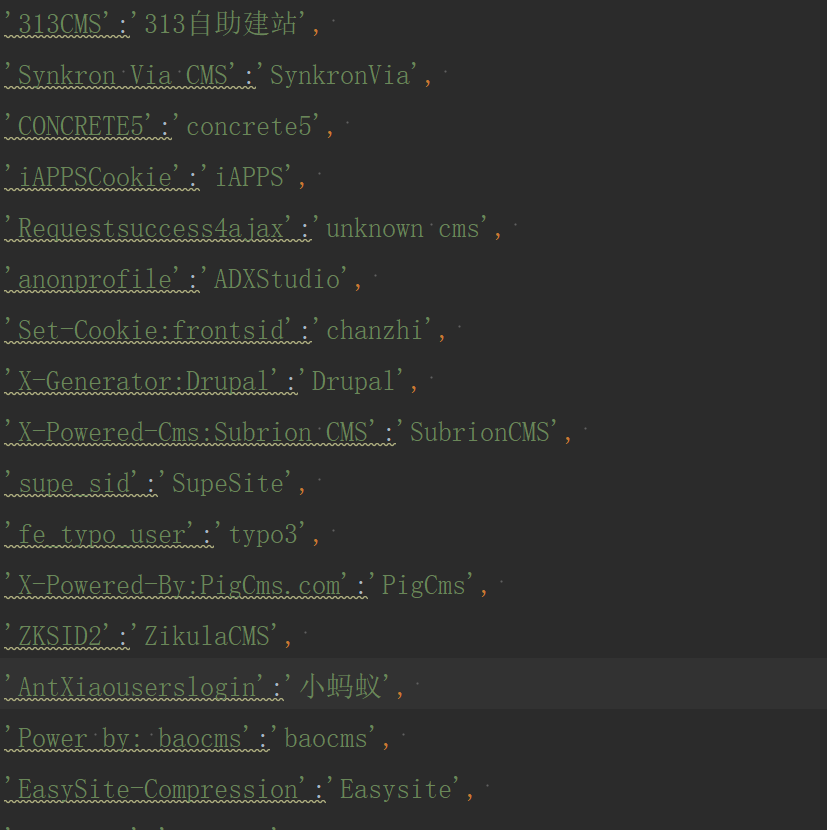
需要注意的是,请求头是一个字典,你需要先把它转换成字符串后,然后再去指纹库寻找特征关键词。
根据robots.txt文件识别CMS类型
渗透测试中,robots.txt一定是都会尝试访问的一个文件,robots协议也叫robots.txt是一种存放于网站根目录下的ASCII编码的文本文件,它通常告诉网络搜索引擎的哪些文件目录不能访问,哪些可以访问,网站管理员不想让搜索引擎访问的目录是不是含有敏感信息呢?
答案是的,有些CMS系统会将一些敏感的目录,比如后台管理界面等不允许搜索引擎抓取,也会将一些独特的特征码放入该文件中。目标例子中网站使用的是PHPCMS v9搭建的系统,通过访问robots文件对比特征码就很容易的识别出使用的CMS类型。
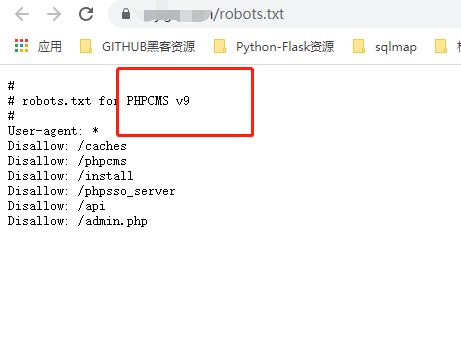
所以还可以根据robots文件的内容方法进行CMS识别。
根据网站文件md5值识别CMS类型
MD5指纹(文件指纹验证)当你从网络上下载了软件后,想确保此软件没有被人修改过(如添加了病毒/非官方插件),或在下载中被破坏,可以用文件指纹验证(MD5)技术进行确认。
原理:
通过某种算法,对具体的文件进行校验,得出了一个32位的十六进制数(校验和)。待校验文件的文件名和后缀名都可以更改,不影响校核。由于原来的信息只要有稍许改动,通过md5运算后,结果都会有很大的改变。所以,如果再次校验以后所得到的值(md5代码)和此软件发布站或官方网站公布的值不同,就可以认为,文件已被改动过。
需要注意的是,每个文件对应的MD5的值是不一样的,那么回归到本文主旨,当你使用一套完整的CMS系统的时候,下载了该CMS系统包含的CSS,字体,图标文件,这些文件中有些都是该CMS特有的,如果访问该文件,然后校验该文件的MD5值,如果与指纹库中一致,则可以判断该网站的CMS类型,该方法相对前面准确率较高。
指纹库格式是这样:
网站文件|CMS类型|网站文件的MD5值。
/static/image/admincp/cloud/qun_op.png|DISCUZ|AB35FA459B0BB01D31BA8FAD0953FCC9|
/widget/images/thumbnail.jpg|ECSHOP|7BB50E4281FA02758834A2E9D7BA9FB9|
/js/calendar/active-bg.gif|ECSHOP|F8FB9F2B7428C94B41320AA1BC9CF601|
/phpcms/libs/data/font/Vineta.ttf|PHPCMS|E6E557BAD69B09533827D9652E0C11AB|
/statics/images/admin_img/arrowhead-y.png|PHPCMS|6C34F70BD2A05C8C5DDEBB369B5B9509|
即网站加上网站文件的网址,获取该文件的MD5值,对照指纹库的值是否一致,如果一致则确认该网站使用的CMS类型。python实现识别方式使用代码实现也就四五行,我们假设案例,假设一个指纹库:
/upload/my_girl.jpg|HEXO|587c7132e6043a1de24e03ededa8980d
然后使用代码实践进行识别:
import hashlib,requests
URL = 'http://www.langzi.fun'
req = requests.get(url=URL+'/upload/my_girl.jpg')
md5 = hashlib.md5()
md5.update(req.content)
if md5.hexdigest() == '587c7132e6043a1de24e03ededa8980d':
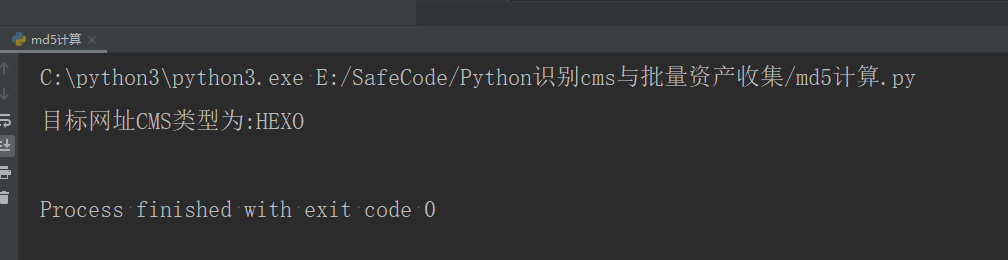
print('目标网址CMS类型为:HEXO')
测试代码结果如下:
根据指定网页内容识别CMS类型
此类方法结合了上面几种情况下的指纹库,即指定CMS系统中默认包含一些网页或者文本,这些文本在你搭建好系统后任然存在,你访问这些网页或者文本,然后查看网页文本中是否存在特定的关键词,如果存在就确认鉴定的CMS类型。
如下文目标网址使用EmpireCMS(帝国网站管理系统)搭建,访问该网站的:
e/admin/adminstyle/1/page/about.htm
文件,发现该页面存在,然后命中关键词,得出结果该网址使用的帝国网站管理系统搭建而成。

字典中触发关键词识别,判定为帝国网址管理系统。

补充说明
除了上面五种访问不同文件类型,然后根据指纹库判定CMS类型,有些时候还可以通过访问错误页面获取信息,这时候可能会遇到防火墙阻拦。
或者有些网站会对目录做一些修改,可以根据实际情况修改扫描代码,自定义添加二级目录扫描对照指纹库有时候也能发现很多敏感信息。
上面五种方法中,按照准确率由高到低排序为:
MD5值校验识别>指定网页内容识别>Robots.txt文件识别>请求头信息识别>首页内容识别
按照扫描需要的时间由低到高排序为:
首页内容识别=请求头信息识别=Robots.txt文件识别>指定网页内容识别>MD5值校验识别
综合性价比由高到低排序为:
Robots.txt文件识别>请求头信息识别>首页内容识别>指定网页内容识别>MD5值校验识别
因为首页内容识别、请求头信息识别、Robots.txt文件识别只用访问一次该网站,不会产生大量的扫描,成功与否主要取决于你的指纹库。如果要扫描指定网页内容和校验MD5值,则会产生较多甚至大量的访问扫描,很容易触发防火墙引起很多麻烦事情上身,当然这些都可以通过降低扫描频率、自动随机切换代理IP、分布式低频率扫描等多种手段绕过。

回归到本文主旨,识别CMS类型最最重要还得依赖强大的指纹库,甚至可以说完全依赖于指纹库的数据,五种方法只是思路的一个分类,能不能产出结果还是要靠指纹库的,关于如何更新整理指纹库,可以在GitHub上收集整理,各大论坛也有好心人专门整理,当然你也可以自己下载多套CMS系统,然后自己分析哪些文件是CMS独有的,校验出MD5值或者考察关键词等等清洗数据后加入更新到你的指纹库。
Python识别CMS代码工程设计实现与拓展
虽然整个工程看上去很多东西挺复杂,但是仔细去分析各个功能模块就会发现很容易实现,你需要做的就是把每个功能单独完成后,整体搭建在一起形成以套流程即可。
综合性价比由高到低排序为:
Robots.txt文件识别>请求头信息识别>首页内容识别>指定网页内容识别>MD5值校验识别
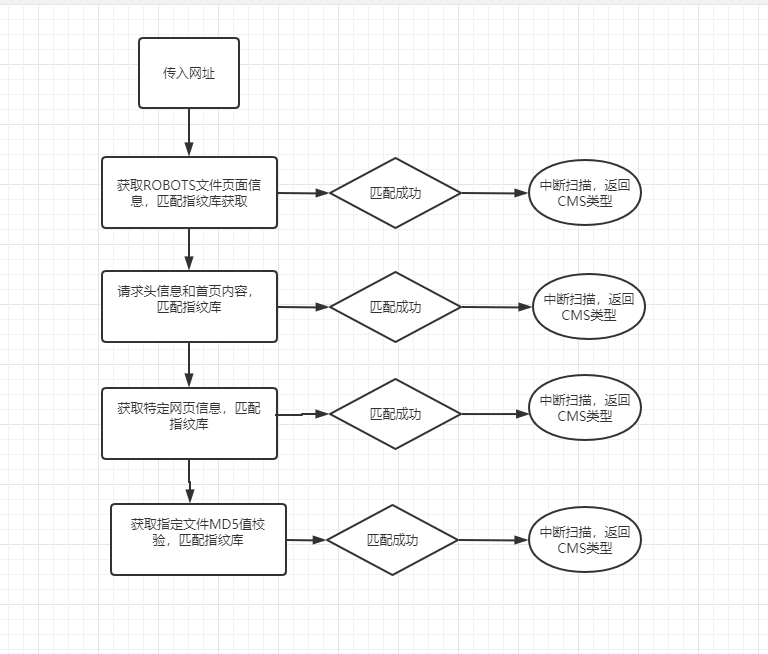
所以只需要访问一次网址的首页,拿到首页内容和请求头信息先对比,访问robots.txt文件检测,最后扫描指定网页内容检测关键词和验证MD5值。
具体流程图:
代码实现如下:
# -*- coding:utf-8 -*-
import requests,hashlib
# 指纹库信息,因为我收集了差不多5000条指纹,如果全部放在代码中,则文章就写不下了
# 本代码仅作演示案例的工程结构
# 关于优化以及拓展,详细会在文章中介绍
# 首页内容指纹库
body = {
'content="WordPress':'WordPress',
'wp-includes':'WordPress',
'pma_password':'phpMyAdmin',
'hexo':'hexo',
'TUTUCMS':'tutucms',
'Powered by TUTUCMS':'tutucms', 'Powered by 1024 CMS':'1024 CMS',
'Discuz':'Discuz',
'1024 CMS (c)':'1024 CMS', 'Publish By JCms2010':'捷点 JCMS',}
# 请求头信息指纹库
head = {'X-Pingback':'WordPress',
'xmlrpc.php':'WordPress', 'wordpress_test_cookie':'WordPress', 'phpMyAdmin=':'phpMyAdmin=',
'adaptcms':'adaptcms',
'SS_MID&squarespace.net':'squarespace建站',
'X-Mas-Server':'TRS MAS',
'dr_ci_session':'dayrui系列CMS',
'http://www.cmseasy.cn/service_1.html':'CmsEasy',
'Osclass':'Osclass',
'clientlanguage':'unknown cms rcms',
'X-Powered-Cms: Twilight CMS':'TwilightCMS',
'IRe.CMS':'irecms',
'DotNetNukeAnonymous':'DotNetNuke',}
# robots文件指纹库
robots = [
'Tncms', '新为软件E-learning管理系统', '贷齐乐系统', '中企动力CMS', '全国烟草系统', 'Glassfish', 'phpvod', 'jieqi', '老Y文章管理系统',
'DedeCMS']
# MD5指纹库
cms_rule = [
'/images/admina/sitmap0.png|08cms|e0c4b6301b769d596d183fa9688b002a|',
'/install/images/logo.gif|建站之星|ac85215d71732d34af35a8e69c8ba9a2|',
'/jiaowu/hlp/Images/node.gif|qzdatasoft强智教务管理系统|70ee6179b7e3a5424b5ca22d9ea7d200|',
'/theme/admin/images/upload.gif|sdcms|d5cd0c796cd7725beacb36ebd0596190|',
'/themes/README.txt|drupal|5954fc62ae964539bb3586a1e4cb172a|',
'/view/resource/skin/skin.txt|未知政府采购系统|61a9910d6156bb5b21009ba173da0919|',
'/theme/admin/images/upload.gif|sdcms|d5cd0c796cd7725beacb36ebd0596190|',
'/images/logout/topbg.jpg|TurboMail邮箱系统|f6d7a10b8fe70c449a77f424bc626680|',]
# 特定网页指纹库
body_rule = [
'/robots.txt|EmpireCMS|EmpireCMS|', '/images/css.css.lnk|KesionCMS(科讯)|kesioncms|',
'/data/flashdata/default/cycle_image.xml|ecshop|ecshop|',
'/admin/SouthidcEditor/Include/Editor.js|良精|southidc|', '/plugin/qqconnect/bind.html|PHP168(国徽)|php168|',
'/SiteServer/Themes/Language/en.xml|SiteServer|siteserver|', '/system/images/fun.js|KingCMS|kingcms|',
'/INSTALL.mysql.txt|Drupal(水滴)|drupal|', '/themes/default/style.css|ecshop|ECSHOP|',
'/hack/gather/template/addrulesql.htm|qiboSoft(齐博)|qiboSoft|',
'/phpcms/templates/default/wap/header.html|phpcms|phpcms']
def GetContent(url):
'''
这个函数功能是:
接受一个传入的网址,返回传入网址的 (请求头信息,原始网页数据,解码成中文后的网页内容)
当然前提是访问成功了
如果访问失败,则直接返回None了
'''
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36'}
try:
r = requests.get(url,timeout=5,headers=headers)
encoding = requests.utils.get_encodings_from_content(r.text)[0]
url_content = r.content.decode(encoding, 'replace')
return (str(r.headers),r.content,url_content)
except:
pass
def CheckCMS(url):
# 根据robots文件判定
url_r = url+'/robots.txt'
res = GetContent(url_r)
if res != None:
for robot in robots:
if robot in res[2]:
return '{}-->CMS类型为:{}'.format(url, robot)
# 然后根据 网页内容和请求头信息判定
res = GetContent(url)
if res != None:
for k,v in head.items():
if k in res[0]:
return '{}-->CMS类型为:{}'.format(url,v)
for k,v in body.items():
if k in res[2]:
return '{}-->CMS类型为:{}'.format(url, v)
# 然后根据特定网址的内容判定
for x in body_rule:
cms_prefix = x.split('|', 3)[0]
cms_name = x.split('|', 3)[1]
cms_md5 = x.split('|', 3)[2]
url_c = url + cms_prefix
res = GetContent(url_c)
if res != None:
if cms_md5 in res[2]:
return '{}-->CMS类型为:{}'.format(url, cms_name)
# 最后根据MD5值判定,其实如果前面都没有判定出来的话,这里扫描的意义也不是很大
for x in cms_rule:
cms_prefix = x.split('|', 3)[0]
cms_name = x.split('|', 3)[1]
cms_md5 = x.split('|', 3)[2]
url_s = url + cms_prefix
res = GetContent(url_s)
if res != None:
md5 = hashlib.md5()
md5.update(res[1])
rmd5 = md5.hexdigest()
if cms_md5 == rmd5:
return '{}-->CMS类型为:{}'.format(url, cms_name)
if __name__ == '__main__':
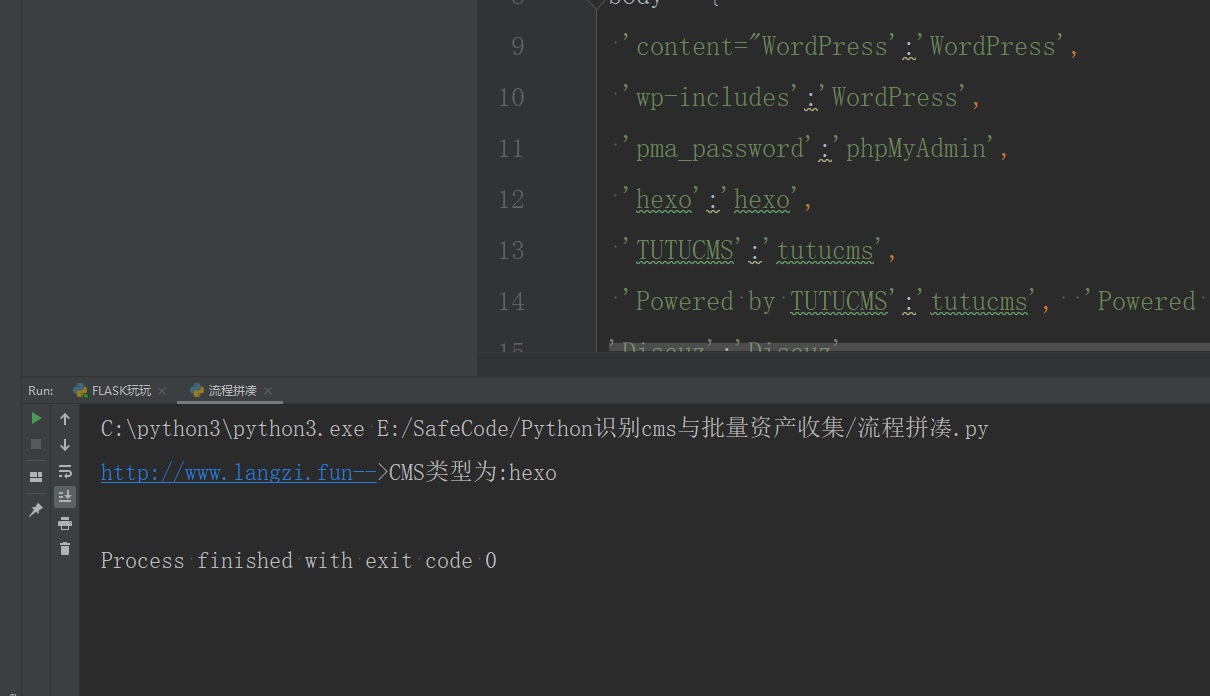
url = 'http://www.langzi.fun'
print(CheckCMS(url))
测试结果:
以上大致就是使用代码识别CMS类型的流程,有代码基础的同学可以自己进行拓展,举几个例子:
- 加入WAF识别功能,即调用特定网页内容鉴定和MD5值校验之前,启动WAF识别,如果发现存在WAF就自行跳过,关于WAF识别的代码在公众号上两篇文章有源代码
- 加入随机请求头,随机代理IP等条件,伪装成浏览器
- 对网站的目录进行爬行,然后抓取爬行网页的内容对比参照指纹库关键词,有些时候也能命中不少,因为一些关键词不一定出现在首页,也有可能出现在错误页面或者404页面中
- 引入线程池,实现批量扫描网址然后识别CMS类型后保存在文本,同样可以实现批量刷洞的效果,不过这种做法有涉及到HC的嫌疑,所以如果不是业务需求还是不要去做
- 寻找多个在线识别CMS的接口,然后写个爬虫,结合在一起识别,当然这个如果作为长期使用的话,还得定期检查接口是否有效
- 单单仅凭靠首页内容关键词判定CMS类型,其实是存在较大的误报率,可以结合robots文件等一起结合判断
- 可以结合其他知识点做出有意思的东西,主要是要把自己的思维拓展开,比如结合Flask做一个简易版在线版识别CMS,也就十几行代码。一时手痒写一个,图个乐吧大家….
代码如下:
# coding:utf-8
from flask import Flask,request
import requests,hashlib
app = Flask(__name__)
body = {
'content="WordPress':'WordPress',
'wp-includes':'WordPress',
'pma_password':'phpMyAdmin',
'hexo':'hexo',
'TUTUCMS':'tutucms',
'Powered by TUTUCMS':'tutucms', 'Powered by 1024 CMS':'1024 CMS',
'Discuz':'Discuz',
'1024 CMS (c)':'1024 CMS', 'Publish By JCms2010':'捷点 JCMS',}
head = {'X-Pingback':'WordPress',
'xmlrpc.php':'WordPress', 'wordpress_test_cookie':'WordPress', 'phpMyAdmin=':'phpMyAdmin=',
'adaptcms':'adaptcms',
'SS_MID&squarespace.net':'squarespace建站',
'X-Mas-Server':'TRS MAS',
'dr_ci_session':'dayrui系列CMS',
'http://www.cmseasy.cn/service_1.html':'CmsEasy',
'Osclass':'Osclass',
'clientlanguage':'unknown cms rcms',
'X-Powered-Cms: Twilight CMS':'TwilightCMS',
'IRe.CMS':'irecms',
'DotNetNukeAnonymous':'DotNetNuke',}
robots = [
'Tncms', '新为软件E-learning管理系统', '贷齐乐系统', '中企动力CMS', '全国烟草系统', 'Glassfish', 'phpvod', 'jieqi', '老Y文章管理系统',
'DedeCMS']
cms_rule = [
'/images/admina/sitmap0.png|08cms|e0c4b6301b769d596d183fa9688b002a|',
'/install/images/logo.gif|建站之星|ac85215d71732d34af35a8e69c8ba9a2|',
'/jiaowu/hlp/Images/node.gif|qzdatasoft强智教务管理系统|70ee6179b7e3a5424b5ca22d9ea7d200|',
'/theme/admin/images/upload.gif|sdcms|d5cd0c796cd7725beacb36ebd0596190|',
'/themes/README.txt|drupal|5954fc62ae964539bb3586a1e4cb172a|',
'/view/resource/skin/skin.txt|未知政府采购系统|61a9910d6156bb5b21009ba173da0919|',
'/theme/admin/images/upload.gif|sdcms|d5cd0c796cd7725beacb36ebd0596190|',
'/images/logout/topbg.jpg|TurboMail邮箱系统|f6d7a10b8fe70c449a77f424bc626680|',]
body_rule = [
'/robots.txt|EmpireCMS|EmpireCMS|', '/images/css.css.lnk|KesionCMS(科讯)|kesioncms|',
'/data/flashdata/default/cycle_image.xml|ecshop|ecshop|',
'/admin/SouthidcEditor/Include/Editor.js|良精|southidc|', '/plugin/qqconnect/bind.html|PHP168(国徽)|php168|',
'/SiteServer/Themes/Language/en.xml|SiteServer|siteserver|', '/system/images/fun.js|KingCMS|kingcms|',
'/INSTALL.mysql.txt|Drupal(水滴)|drupal|', '/themes/default/style.css|ecshop|ECSHOP|',
'/hack/gather/template/addrulesql.htm|qiboSoft(齐博)|qiboSoft|',
'/phpcms/templates/default/wap/header.html|phpcms|phpcms']
def GetContent(url):
'''
这个函数功能是:
接受一个传入的网址,返回传入网址的 (请求头信息,原始网页数据,解码成中文后的网页内容)
当然前提是访问成功了
如果访问失败,则直接返回None了
'''
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36'}
try:
r = requests.get(url,timeout=5,headers=headers)
encoding = requests.utils.get_encodings_from_content(r.text)[0]
url_content = r.content.decode(encoding, 'replace')
return (str(r.headers),r.content,url_content)
except:
pass
def CheckCMS(url):
# 根据robots文件判定
url_r = url+'/robots.txt'
res = GetContent(url_r)
if res != None:
for robot in robots:
if robot in res[2]:
return '{}-->CMS类型为:{}'.format(url, robot)
# 然后根据 网页内容和请求头信息判定
res = GetContent(url)
if res != None:
for k,v in head.items():
if k in res[0]:
return '{}-->CMS类型为:{}'.format(url,v)
for k,v in body.items():
if k in res[2]:
return '{}-->CMS类型为:{}'.format(url, v)
# 然后根据特定网址的内容判定
for x in body_rule:
cms_prefix = x.split('|', 3)[0]
cms_name = x.split('|', 3)[1]
cms_md5 = x.split('|', 3)[2]
url_c = url + cms_prefix
res = GetContent(url_c)
if res != None:
if cms_md5 in res[2]:
return '{}-->CMS类型为:{}'.format(url, cms_name)
# 最后根据MD5值判定,其实如果前面都没有判定出来的话,这里扫描的意义也不是很大
for x in cms_rule:
cms_prefix = x.split('|', 3)[0]
cms_name = x.split('|', 3)[1]
cms_md5 = x.split('|', 3)[2]
url_s = url + cms_prefix
res = GetContent(url_s)
if res != None:
md5 = hashlib.md5()
md5.update(res[1])
rmd5 = md5.hexdigest()
if cms_md5 == rmd5:
return '{}-->CMS类型为:{}'.format(url, cms_name)
@app.route('/')
def index():
return '''
<title>CMS识别在线系统</title>
<form method="post" action="cms">
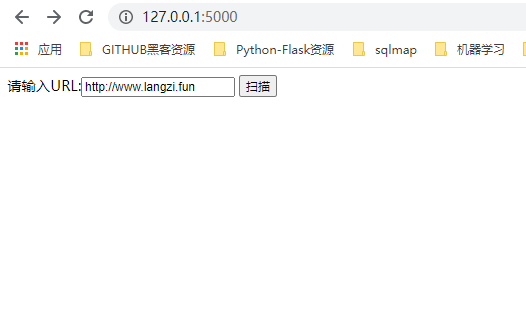
请输入URL:<input name="url" value='http://www.langzi.fun'/>
<button>扫描</button>
</form>
'''
@app.route('/cms',methods=['GET','POST'])
def post_():
url = request.form['url']
cms = CheckCMS(url)
return "识别结果:{}".format(cms)
if __name__ == '__main__':
app.run(debug=True,host='0.0.0.0')
访问IP+5000端口访问
扫描结果:
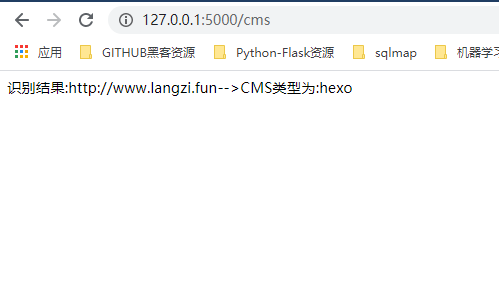
其实还是挺好玩的啦~
指纹库获取
在Github,一些论坛,收集整理了许多指纹并做了数据清洗分类(截至到2019年),有需要的同学可以在本公众号回复关键词:【指纹库】,获取指纹库下载地址。


