优秀的人,不是不合群,而是他们合群的人里面没有你
前情提要
U2f这种的基本要用线上解密,可能需要密钥,比如ase,des,用网址
http://www.jsons.cn/desencrypt/
编码和解码
ascii
长这个样子,由十进制-二进制-符号组成,ascii码由八位二进制组成
65 01000001 A 0x11 011
十进制 二进制 符号 十六进制 八进制
要对一些重点十进制和二进制敏感一些,比如flag对应的
70 01000110 F
76 01001100 L
102 01100110 f
108 01101100 l
可以注意到,所有的二进制都是八位连在一起的,并且都是0开头。
贴下各类flag的加密密文: flag是flag
01100110 01101100 01100001 01100111是flag(二进制)
146 154 141 147 是flag(八进制)
102 108 97 103 是flag(十进制)
66 6c 61 67是flag(十六进制)
ZmxhZ是flag(base64)
MZWGCZ是flag(base32)
synt是flag(rot13)
…-. .-… .- --.是flag(莫斯码)
21 31 11 22是flag(敲击码)
AABAB ABABB AAAAA AABBA是flag(培根密码)
所以能出的题型大概如下两种:
第一种
如果你得到一大串二进制文本,数量不能整除8,但是能整除7,就要有警惕心,可以分成7分,然后在每一行加上0尝试一下啊。如果能整除5,可以考虑培根密码。如果能够开方,可以考虑二维码。
如果给你一大串十进制的数值,那就更爽啦,要有这个警惕性!!!
二进制,八进制转换成ascii码,python下用这个脚本实现:
data = 011
res = chr(int(d,8))
八进制转ascii
data = 01000100
res = chr(int,2)
二进制转ascii
ciphertext = bytes('flag{xxxxxxxxx}')
hex_value = ciphertext.hex()
# "9b919c9a8685cd8fa294c8a28c88cc89cea2ce9c878480"
binary_value = bytes.fromhex(hex_value)
print(binary_value[0])
有时候随波逐流解不开,可以用那个CyberChef网页,点击这个魔术手,可以自动解码,爽歪歪~
二进制开方转二维码,举个例子就明白了
给出来的题目长这样:
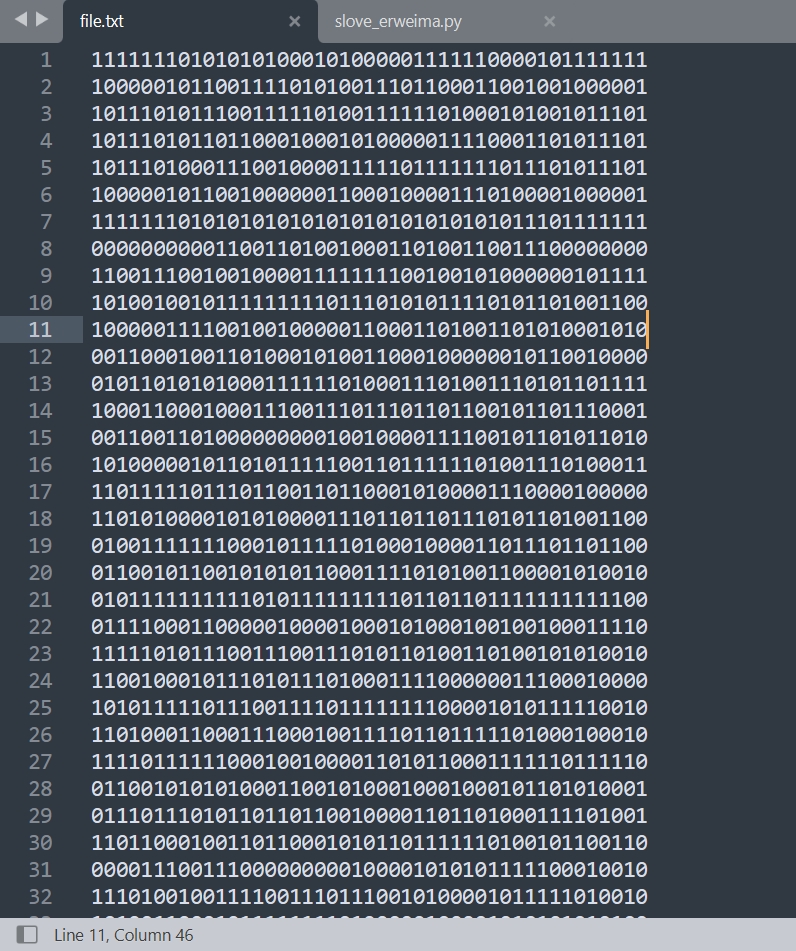
横着长度45列,竖着长度45行,而且只有01,就是可以理解为01对应于二维码的黑白,可以使用脚本直接解决:
from PIL import Image
x = 45
y = 45
im = Image.new('RGB', (x, y))
white = (255, 255, 255)
black = (0, 0, 0)
with open('file.txt') as f:
for i in range(x):
ff = f.readline()
for j in range(y):
if ff[j] == '1':
im.putpixel((i, j), black)
else:
im.putpixel((i, j), white)
im.save("1.jpg")
或者用随波逐流工具,文件-10转图片,然后扫描就行,不用放大,直接扫描。有时候可能出不来结果,多生成两种试试看
第二种
因为设计到二进制数据,二进制无非01,那么01是不是可以用别的代替,比如大量AB这样的字符串出现,或者大量,。这样的符号出现,以及波形图出现,都可以尝试替换成01,然后带入解密~~总结就是密文只有两种形态
发现一个很绝的出题思路,无语了真想暴打出题人,给的题目如下:
83,121,110,116,71,115,121,110,116,136
一看像ascii,但是解密不对,然后发现规律,flag对应的ascii应该是 102,108,97,103每一位和密文都差了13个整数,懂我意思吧…
使用python脚本
a=[83,121,110,116,71,115,121,110,116,136,135,120,135,108,110,126,115,112,63,61,63,62,108,67,63,69,108,76,76,76,76,138,90,113,66,71,112,110,66,62,62,67,112,112,66,111,112,67,113,63,110,114,69,66,65,110,111,111,113,68,61,63,112,69,68,68,68]
for i in a:
j = chr(i-13)
flag="".join(j)
print(flag)
然后就是升级问题了,解码出来的值就是:
Flag:flag{zkz_aqfc2021_628_????}Md5:ca5116cc5bc6d2ae854abbd702c8777
意思就是这个flag整个字符串经过md5加密后的值是ca5116cc5bc6d2ae854abbd702c8777,然后四个?代表四个未知数。这个时候逐个碰撞测试就知道了,附上脚本
import hashlib
flag_md5 = 'ca5116cc5bc6d2ae854abbd702c8777d'
strs = "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ!#$%&()*+,-./:;<=>?@[\]^_`{|}~ "
for a in strs:
for b in strs:
for c in strs:
for d in strs:
md5 = hashlib.md5()
flag = 'flag{zkz_aqfc2021_628_' +str(a)+str(b)+str(c)+str(d)+'}'
md5.update(flag.encode())
if md5.hexdigest() == flag_md5:
print(flag)
另外一种思路就是不同的进制文件放在一起,比如:
014 1011010 0115 1101011 0122 0116 1010100 0153 1110000 1011000 1010010 060 1101100 1100001 0126 0106 1001110 1001110 0127 1101100 0160 1001000 0124 1010100 1001110 0105 1010010 060 065
第一眼没有什么头绪,但是仔细发现其中三位数的是八进制,八位数的是二进制,那么写一个脚本直接转码吧~
data = '0105 1010110 1001111 1010101 1101100 1010110 0110 0127 1010100 1001010 1000101 1010100 1010101 110001 1010011 0126 060 1100100 1010110 1001101 060 1010010 0110 0124 0126 0160 0141 0122 060 061 0141 1010110 1000101 061 1001111 1010011 0154 0122 1001000 0126 1010100 1001110 0105 1010010 110000 110001 1100001 0126 110000 1100100 0132 1010111 0126 1010010 1001000 0124 0154 1001010 1011001 1010100 0126 0105 071 0120 0124 060 111001 0120 1010100 110000 111101'
data = data.split()
flag = ''
for d in data:
if len(d)>4:
flag+=chr(int(d,2))
else:
flag+=chr(int(d,8))
print(flag)
base64/32
这种密文组成包含大小写字母和0-9组成,然后后面只可能会有一个最多两个=符号。
baee64和base32和base16数字的区别在于用多少个字符来编码。
base32可以在最后有三个或者四个或者五六个=符号来填充。
base16就是base的16进制,密文形式就是全数字,很多的数字。也能有字母,主要特征就是数字和字母拼接凑合很多,但是最后不能有=符号。
这种题难度在于多次base64加密,或者32和64多次一起加密。
多次base64解密的密文特征是特别长…
另外汇总一下:
base64:A-Za-z0-9+/
base32:A-Z2-7
base16:0-9A-F
有个变态的傻逼问题
题目这个逼样:
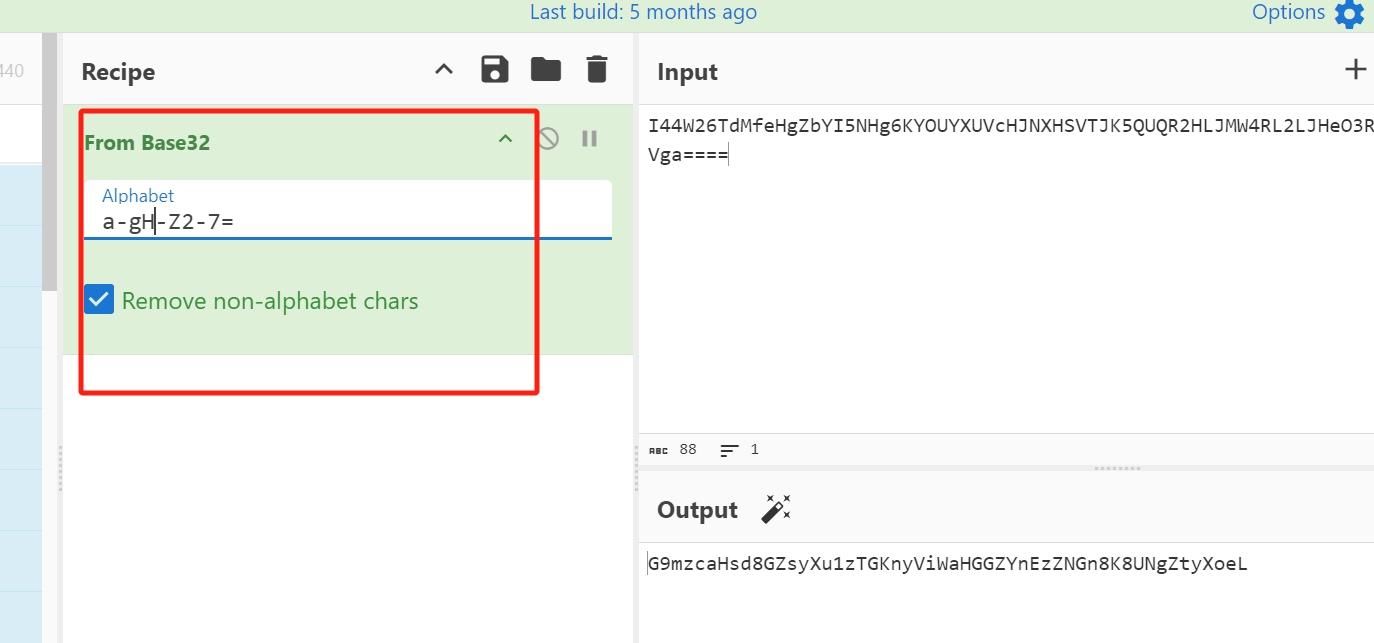
I44W26TdMfeHgZbYI5NHg6KYOUYXUVcHJNXHSVTJK5QUQR2HLJMW4RL2LJHeO3RYJM4fKTTHLJ2HSWdPMVga====
没发一键梭哈,但是随波发现base32编码后,在编码一下。
另外一种方法就是看,看大小写的规律,然后这样子出来
然后有个奇葩的情况,就是不同类型的编码加密,比如utf-8编码的数据和unicode编码的数据,经过base64加密后的内容是不一样的
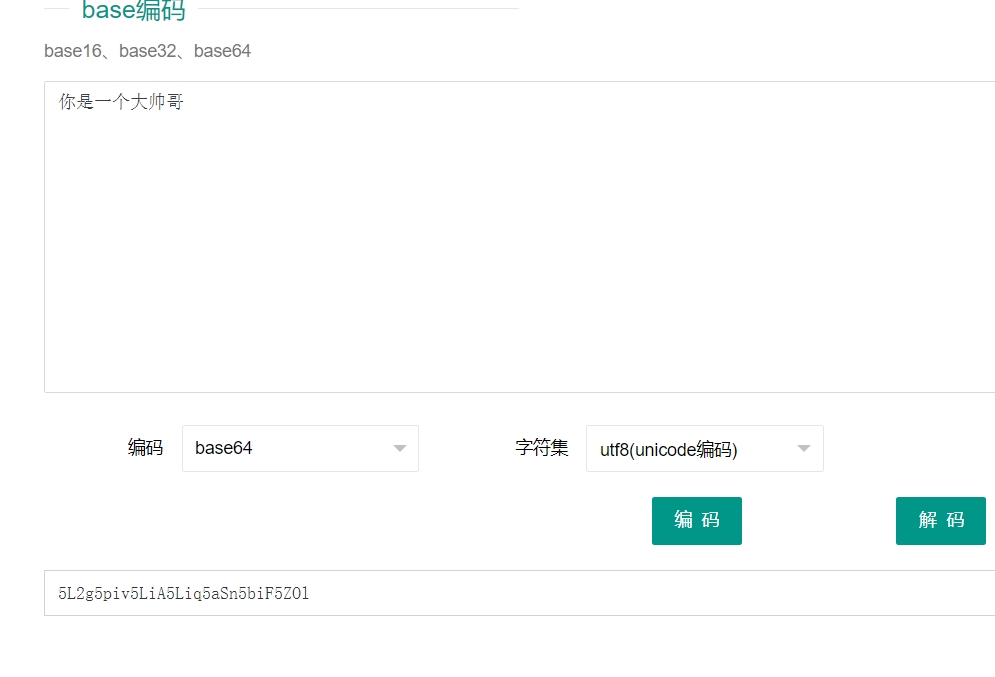
随波逐流和CyberChef只能识别出utf-8编码加密的,如果解码unicode加密的,就用小葵的那个编码转换器
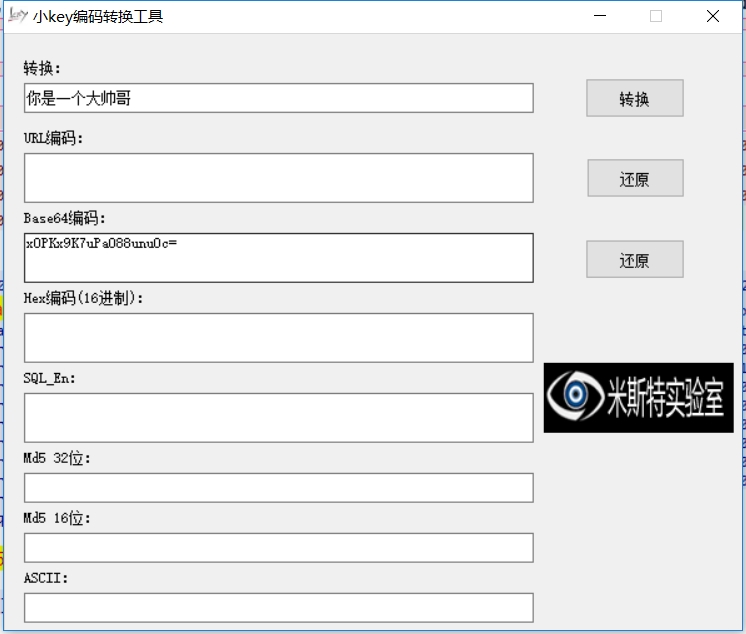
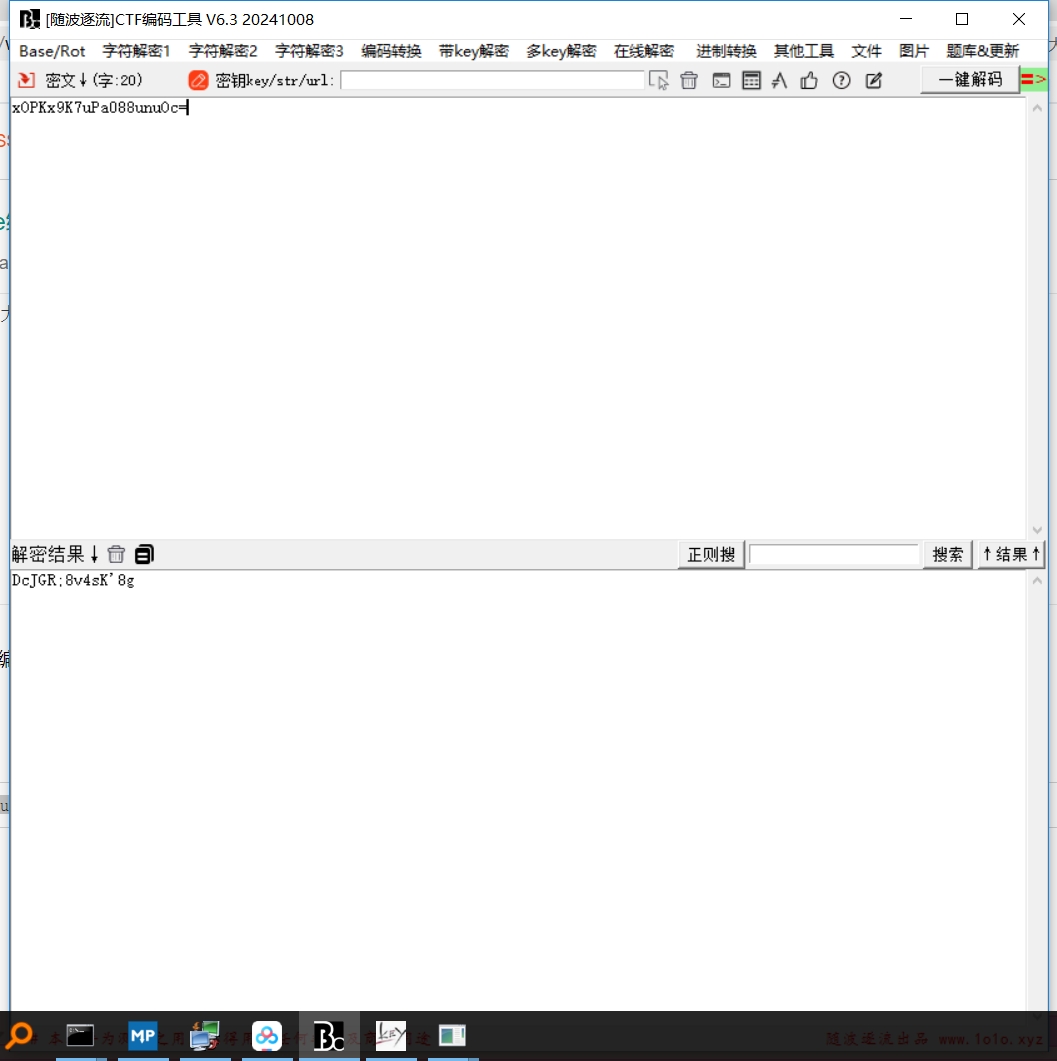
url编码
也叫百分号编码,原理是在该字符的ascii码的16进制字符前面加上%,比如空格字符,ascii码是32,对应16进制是20,那么空格的url编码就是%20
双重编码
> 正常url编码是 %3c
%3C 进行url编码 %253C
*****双重编码后*****
%253c 解密后 %3c
这就意味着,可以绕过一些对<符号的过滤
同样在sql注入中也可以用
unicode编码
ascii只能翻译字母数字,为了全球文本都能用,于是unicode诞生!
一般的格式如下
格式:您好
格式:\u60a8\u597d
格式:您好
格式:\U+0054\U+0068\U+0065
长得这个鬼样子都是unicode编码,可以用工具进行解码,或者内容保存为xx.html然后用浏览器打开也能解密。
Quoted-printable编码
这个鬼东西我也是第一次见,叫可打印字符引用编码。
这个东西长这样
=CE=D2=F3=GA=SV=E3
XXencode编码
XXencode 将输入文本以每三个字节为单位进行编码。如果最后剩下的资料少于三个字节,不够的部份用零补齐。
跟 base64 打印字符相比,就是 UUencode 多一个 - 字符,少一个 / 字符。
源文本: The quick brown fox jumps over the lazy dog
编码后: hJ4VZ653pOKBf647mPrRi64NjS0-eRKpkQm-jRaJm65FcNG-gMLdt64FjNkc+
揭秘网站
http://web.chacuo.net/charsetxxencode
UUencode编码
UUencode是一种二进制到文字的编码,所产生的结果刚好落在ASCII字符集中可打印字符(32-空白…95-底线)的范围之中。
源文本: The quick brown fox jumps over the lazy dog
编码后: M5&AE('%U:6-K(&)R;W=N(&9O>"!J=6UP<R!O=F5R('1H92!L87IY(&1O9PH*
编码解码
http://web.chacuo.net/charsetuuencode
Shellcode编码
这玩意实际就是一段代码,用来发送到服务器利用漏洞的代码。
这玩意长这样
\x54\x68\x6c\x61
是不是和16进制hex编码长得一脉一样,其实就是把明文的字母对应的10进制转换成16进制,然后加上\x一起。
Escape编码
这个编码主要是为了处理乱码的问题,原理是将字符替换成十六进制的序列,不对ascii字母和数字还有符号编码,将中文统一编码。
实现方式就是使用JavaScript的escape对数据进行编码,然后在服务器段进行解码。
主要特征:对字母,数字,符号不编码,对中文编码
长这样:
hello%u554A%u4F60%u771F%u662F%u516D%u554A666
解密后:
hello你真6啊
html实体编码
html语言需要用比如<这种符号,但是和加密分来,所有html编码要对一些符号进行编码处理。
比如:
<p>hello</p> 编码后 <p>hello</p>
好好好 编码后 好好好
敲击码
敲击码(Tap code)是一种以非常简单的方式对文本信息进行编码的方法。
主要表现特征是这个样子
明文 F o x
位置 2,1 3,4 5,3
敲击码 .. . … …. ….. …
有在线解密网址
摩斯密码
摩尔斯电码主要由以下5种它的代码组成:
点(.)
划(-)
每个字符间短的停顿(通常用空格表示停顿)
每个词之间中等的停顿(通常用 / 划分)
以及句子之间长的停顿
一般来说长这样
- .... . / --.- ..- .. -.-. -.- / -... .-. --- .-- -. / ..-. --- -..- / .--- ..- -- .--. ... / --- ...- . .-. / - .... . / .-.. .- --.. -.-- / -.. --- --.
但是要注意的是,有时候这些符号可以用别的特征的字符或者符号代替要有这个意识和警惕性!!
文本加密成汉字
这个更牛了,密文就是汉字,可能是没有意义的汉字长得乱七八糟,反正看看,格式如下
明文:你好
密文:证喊枨兮==
明文:flag{admin666}
密文:圯这奴撺籍奴启榻枨喵恫恫恫馑=
揭秘网站
https://www.qqxiuzi.cn/bianma/wenbenjiami.php
特殊编码
音符解码
长这个逼样
♭‖♭‖‖♯♭♭♬‖♩♫‖♬∮♭♭¶♭‖♯‖¶♭♭‖∮‖‖♭‖§♭‖♬♪♭♯§‖‖♯‖‖♬‖‖♪‖‖♪‖¶§‖‖♬♭♯‖♭♯
解码网站
https://www.qqxiuzi.cn/bianma/wenbenjiami.php?s=yinyue
丑逼加密
长这样的丑逼还在笑
( ͡° ͜ʖ ͡°)( ͡° ͜ʖ ͡°)( ͡° ͜ʖ ͡°)( ͡° ͜ʖ ͡°)( ͡° ͜ʖ ͡°)
用颜文字对照表
https://esolangs.org/wiki/(_%CD%A1%C2%B0_%CD%9C%CA%96_%CD%A1%C2%B0)fuck
逐个解密
颜文字,多个字符加密
比如很明显的字符组成的多个数据
゚ω゚ノ= /`m´)ノ ~┻━┻ //*´∇`*/ ['_']; o=(゚ー゚) =_=3; c=(゚Θ゚) =(゚ー゚)-(゚ー゚); (゚Д゚) =(゚Θ゚)= (o^_^o)/ (o^_^o);(゚Д゚)={゚Θ゚: '_' ,゚ω゚ノ : ((゚ω゚ノ==3) +'_') [゚Θ゚] ,゚ー゚ノ :(゚ω゚ノ+ '_')[o
直接复制,然后在浏览器控制台输入运行就可以
跳舞小傻逼
很多小鸡吧在跳舞,对照表解密
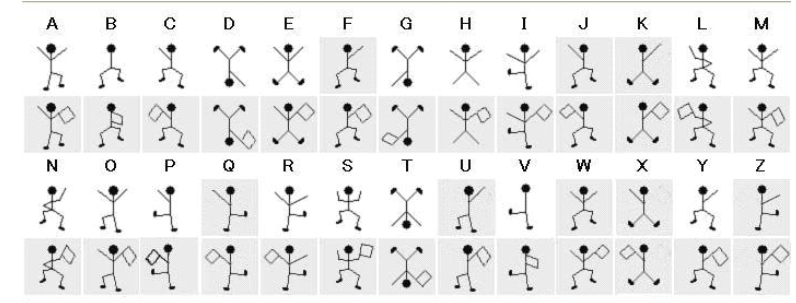
表情加密

密文就是一大串的emoji表情符号,是图片表情符号哦
使用在线解密网址
https://aghorler.github.io/emoji-aes/
二进制转文本工具
长这个逼样
0010110011000100100100111001101010100001
解码网站
https://coding.tools/cn/binary-to-text
转换成十进制或者文本,看结果而论,如果转出6 18 26 25,可以参考对应字母表,破解出明文为frzy….无语了
字母加密
长得很像base62/32这种,纯纯的字母,居然还带个=号,给我纠结半天
解密网址
https://www.qqxiuzi.cn/bianma/wenbenjiami.php?s=zimu
rabbit解密
解码网站
http://www.atoolbox.net/Tool.php?Id=679
需要输入key
花朵加密
长这样
❀✿✼❇❃❆❇✿❁❇✻✿❀✾✿✻❀❊❆❃❀❊✻❅❀❄✼❂❊❊✾❇❁✽✽✼❁❂❀❀❀❉❃❂❀❉❃❂❊❊✾✼✻✻❀❆✻✻❀❀✻✻✿❄✻✻✿❆✻✻✿❂✻✻❀❀✻✻❀❇✻✻❀✾✻✻❀❊✻✻❀❈✻✻❀❀✻✻❁❊✻✻✿✿✻✻❀❊✻✻❁❊✻✻❀✾✻✻✿✿✻✻❀❁✻✻✿❈==
用随波逐流工具箱

字母密码,音符密码也用工具箱都有
直接解码
可以直接对照表进行~
栅栏密码传统
即把将要传递的信息中的字母交替排成上下两行,再将下面一行字母排在上面一行的后边,从而形成一段密码。
举例:
TEOGSDYUTAENNHLNETAMSHVAED
解:
将字母分截开排成两行,如下
T E O G S D Y U T A E N N
H L N E T A M S H V A E D
解密网站或者用随波工具箱
http://www.atoolbox.net/Tool.php?Id=855
栅栏密码w
http://www.atoolbox.net/Tool.php?Id=777
ADFGVX加密
一战的时候德国用过的加密,密文格式如下
FA XX DD AG DD XA FF FF AX DX
对照解密表

凯撒密码
也就是一种最简单的错位法,将字母表前移或者后错几位,例如:
明码表: ABCDEFGHIJKLMNOPQRSTUVWXYZ
密码表: DEFGHIJKLMNOPQRSTUVWXYZABC
解密网站
https://www.qqxiuzi.cn/bianma/kaisamima.php
猪圈密码
对应符号找字母,没啥区别,就是长这样,要有印象
在这网站解密,或者随波工具
https://www.xiao84.com/tools/103177.html
莫斯密码
没什么好说的,一长一短滴滴滴,长得这样
..-.
....
..-.
.-..
--.-
如果没法一次性全部解密,就逐个测试
https://tool.bugku.com/mosi/
替换密码(埃特巴什码)
这两个原理一样,放在一起说,
埃特巴什码(Atbash Cipher)其实可以视为下面要介绍的简单替换密码的特例,它使用字母表中的最后一个字母代表第一个字母,倒数第二个字母代表第二个字母。在罗马字母表中,它是这样出现的:

简单的很,替换密码原理一样,但是要有一个对应表,将每个明文字母替换为与之唯一对应且不同的字母。它与恺撒密码之间的区别是其密码字母表的字母不是简单的移位,而是完全是混乱的,这也使得其破解难度要高于凯撒密码

而解密时,我们一般是知道了每一个字母的对应规则,才可以正常解密,由于这种加密方式导致其所有的密钥个数是26! ,所以几乎上不可能使用暴力的解决方式。所以我们一般采用词频分析
使用网址或者随波工具
http://quipqiup.com/
培根密码
好像只有AB
https://tool.bugku.com/peigen/
有个很阴毒的办法,就是你得到的密文是一串01或者只有两个特征的符号,你以为是二进制,发现无法解密…
可以尝试转换成AB培根密码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
## Playfair普来费尔
是一种替换密码,
1、 选取一串英文字母, 除去重复出现的字母, 将剩下的字母逐个逐个加入 5 × 5 的矩阵内, 剩
下的空间由未加入的英文字母依 a-z 的顺序加入。 注意, 将 q 去除, 或将 i 和 j 视作同一字。
2、 将要加密的明文分成两个一组。 若组内的字母相同, 将 X(或 Q) 加到该组的第一个字母后,
重新分组。 若剩下一个字, 也加入 X 。
3、 在每组中, 找出两个字母在矩阵中的地方。
## 敲击码
http://www.hiencode.com/tapcode.html
## 棋盘密码
https://www.qqxiuzi.cn/bianma/qipanmima.php
## 关键词密码
维吉尼亚密码唯一需要key的古典加密,维吉尼亚密码(Vigenere)是在凯撒密码基础上产生的一种加密方法,它将凯撒密码的全部25种位移排
序为一张表,与原字母序列共同组成26行及26列的字母表。另外,维吉尼亚密码必须有一个密钥,这个密钥由字母组成,最少一个,最多可与明文字母数量相等
解密网站-已知秘钥
https://www.qqxiuzi.cn/bianma/weijiniyamima.php
http://www.hiencode.com/keyword.html
解密网站-不知秘钥
https://www.mygeocachingprofile.com/codebreaker.vigenerecipher.aspx
https://www.guballa.de/vigenere-solver
**注意咯!!里面的语言不仅仅是english,如果解出来的不是flag字样,多试一试别的比如french,等等**
还有现成的脚本,使用方法如下:
python2 break_vigenere.py
在reak_vigenere.py文件内替换加密后的就
我放在upload目录下的Vigene.rar
## 当铺密码
真奇怪的名字....
当前汉字有多少笔画出头,就是转化成数字几,
这种加密算法相当简单:当前汉字有多少笔画出头,就是转化成数字几。
王:该字外面有 6 个出头的位置,所以该汉字对应的数字就是 6;
口:该字外面没有出头的位置,那就是0;
人:该字外面有 3 个出头的位置,所以该汉字对应的数字就是 3;比如:

长得这个鬼样子,丢随波工具箱
像这样的也是

base64
https://www.qqxiuzi.cn/bianma/base64.htm
base32
https://www.qqxiuzi.cn/bianma/base.php
与佛论禅:
http://www.keyfc.net/bbs/tools/tudoucode.aspx
社会主义核心价值观编码:
http://www.atoolbox.net/Tool.php?Id=850
Ook!:
长的这个样子:
Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook.
Ook. Ook! Ook? Ook! Ook! Ook. Ook? Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook.
Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook? Ook. Ook? Ook! Ook. Ook? Ook.
如果你发现,解密后的密文是长得差不多这样
cat. cat. cat. cat. cat. cat. cat. cat. cat. cat. cat. cat. cat. cat. cat.
cat. cat! cat? cat! cat! cat. cat? cat. cat. cat. cat. cat. cat. cat. cat.
cat. cat. cat. cat. cat. cat. cat. cat. cat? cat. cat? cat! cat. cat? cat.
cat. cat. cat. cat. cat. cat! cat. cat! cat! cat! cat! cat! cat. cat? cat.
cat. cat. cat. cat. cat. cat. cat. cat. cat! cat? cat! cat! cat. cat? cat.
cat. cat. cat. cat. cat. cat. cat. cat? cat. cat? cat! cat. cat? cat. cat.
不妨替换成Ook在解密,随波逐流工具箱只能解密Ook,但是网址可以对变形后的进行解密
https://www.splitbrain.org/services/ook
也属于Brainfuck
Brainfuck:
https://www.splitbrain.org/services/ook
包含特征的密码
云影密码(只有01248)
Jsfuck
组成符号有([]()!+)
直接在浏览器执行就行
词频分析
共工具一下出来,但是要记住题目长什么样
仿射密码
这个其实比较难,涉及到算法,但是安全性比较弱,所以放在这里,它的原理如下:
'''
仿射密码K = (a,b)
加密函数是E(x)= (ax + b) (mod 26)
cipher = (a*plain + b) (mod 26)
# ciper 密文 ,plain是明文 ,a,b是固定数字,plain是明文对应的数字,比如a-0,b-1
解密函数为D(x) = (a^-1)(x - b) (mod 26),其中a^-1是a的乘法逆元
# plain = ((cipher - b) * gmpy2.invert(a,m)) (mod m)
推b:
b = (cipher - a * plain) mod m
推a:
cipher1 = (a * plain1 + b) mod m
cipher2 = (a * plain2 + b) mod m
==> cipher1 -cipher2 = a * (plain1 - plain2 ) mod m
==> a = ((cipher[2] -cipher[1]) * gmpy2.invert((plain[2] - plain[1]) , m)) mod m
==> 那么更加简单
a = (cipher[2]-cipher[1])*gmpy2.invert(ord('a')-ord('l'),m)%m
# 其中cipher的值是已经知道的,m已经知道的,plain也是已经知道前面是flag
b = (ciper[2] - a*ord('a'))%m
'''
通过代码案例展示:
# 加密
def enc(a, b, e):
c = []
for i in e:
temp = ((ord(i) - 97) * a + b) % 26 + 97 # a的ascii码是97
c.append(chr(temp))
print(''.join(c).upper())
# 遍历得到a的乘法逆元
def get_multiplicative_inverse(a):
for i in range(1, 27):
if a * i % 26 == 1:
return i
# 解密
def dec(a, b, d):
a_mul_inv = get_multiplicative_inverse(a)
p = []
for i in d:
temp = (((ord(i) - 97) - b) * a_mul_inv) % 26 + 97
p.append(chr(temp))
print(''.join(p).upper())
if __name__ == "__main__":
a, b = 7, 3
e = 'hot'
# d = 'axg'
enc(a, b, e)
# dec(a, b, d)
给个题目吧
from flag import flag, key
modulus = 256
ciphertext = []
for f in flag:
ciphertext.append((key[0]*f + key[1]) % modulus)
print(bytes(ciphertext).hex())
# dd4388ee428bdddd5865cc66aa5887ffcca966109c66edcca920667a88312064
解答思路有2种,第一个是正儿八经解答,第二个是爆破
正儿八经解答,那么对应解题脚本就是:
import gmpy2
from Crypto.Util.number import *
hex_value = 'dd4388ee428bdddd5865cc66aa5887ffcca966109c66edcca920667a88312064'
xxx = bytes.fromhex(hex_value)
# 第一步转换格式返回到bytes类型,bytes直接打印出来就是数字,可以直接操作加减乘除
ddd = 'flag{xxxxxx}'
# 我已知的是flag的前面字符串一定是flag
print(xxx)
import gmpy2
from Crypto.Util.number import *
print((xxx[1]))
print((xxx[2]))
print(ord(ddd[1]))
print(ord(ddd[2]))
# 默认用第二个,第三个字符串进行运算
print('----------------')
plaindelta = ord(ddd[2]) - ord(ddd[1])
print(plaindelta)
cipherdalte = xxx[2] - xxx[1]
print(cipherdalte)
modulus = 256
# 已知的
a = gmpy2.invert(plaindelta, modulus) * cipherdalte % modulus
# 通过这公式求出a
b = (xxx[1] - a * ord(ddd[1])) % modulus
# 通过公式求b
print(a,b)
a_inv = gmpy2.invert(a, modulus)
result = ""
for c in xxx:
result += chr((c - b) * a_inv % modulus)
print(result)
还可以这样写:
import gmpy2
m=256
cipher = bytes.fromhex('dd4388ee428bdddd5865cc66aa5887ffcca966109c66edcca920667a88312064')
a = (cipher[2]-cipher[1])*gmpy2.invert(ord('a')-ord('l'),m)%m
# 固定公式
# 其中cipher的值是已经知道的,m已经知道的,plain也是已经知道前面是flag
b = (cipher[2] - a*ord('a'))%m
# 固定公式,这一步是求出b
print(a,b)
flag = ''
#plain = ((cipher - b) * gmpy2.invert(a,m)) (mod m)
# 获取明文的公式
for i in cipher:
flag+=chr((i-b)*gmpy2.invert(a,m)%m)
# 这里的i和b
print(flag)
无赖一点直接爆破
import gmpy2
from Crypto.Util.number import *
c = 'dd4388ee428bdddd5865cc66aa5887ffcca966109c66edcca920667a88312064'
m = 256
def mul(k0, k1, c):
ciphertext = bytes.fromhex(c)
# print(str(ciphertext))
clist = []
for f in ciphertext:
if gmpy2.gcd(k0, m) != 1:
continue
else:
clist.append(((f-k1) * gmpy2.invert(k0, m)) % m)
# lis_byd = bytes(clist)
# print(clist)
return ''.join(chr(i) for i in clist)
for k0 in range(1, 255, 2):
for k1 in range(1, 255):
if 'flag' in mul(k0, k1, c):
ans = mul(k0, k1, c)
print(k0, k1, ans)
else:
continue

