一切就像写在预言书中的末日,末日面前每个人都渺小的像是尘埃。
Lang_cms_find 2.0
目录下就只有两个文件:
Lang_CMS_Find_2.0_高配版.exe
// 启动主程序,内置2400+CMS识别指纹
Config.ini
// 配置文件,设置数据库账号密码,端口和线程数
使用说明
Lang_CMS_Find_2.0_高配版.exe
自动化无限CMS采集
运行要求:
1 MYSQL已安装
2 CPU:2核或以上
3 内存:4G或以上
4 宽带:10M或以上
5 最低线程数: 20或以上
2.0 vs 1.0
跟新说明:
1 新增CMS识别指纹,约2400条请求验证CMS类型
2 数据库索引优化
3 关键词采集支持中文
2018年7月19日23:04:09
采集到的CMS会自动保存在result.txt,每10分钟就会在数据库中提取刷新一次结果。
因为我的台式机使用的是8G+4H+100M的宽带,测试开启100个线程完全无压力
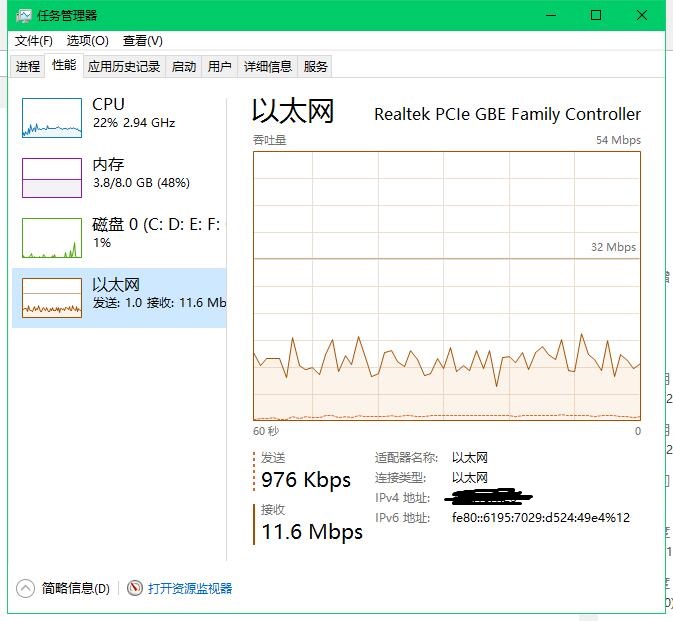
但是我的服务器配置比较低,还要运行很多别的服务,于是稍微调了一下参数,服务器版本强制使用5个线程,勉强还可以。
使用方法还是和之前的一样

内置指纹数量增加,现在CMS识别率可以达到40-60%左右,也就是说10个网址可以识别出4个左右的CMS(关键的这10个网址都是随机选择的,有些网址是自己写的没有使用CMS)。

服务器使用5个线程,挂机跑了一个月,一共采集到10748条CMS,数据库是自动去重复的。
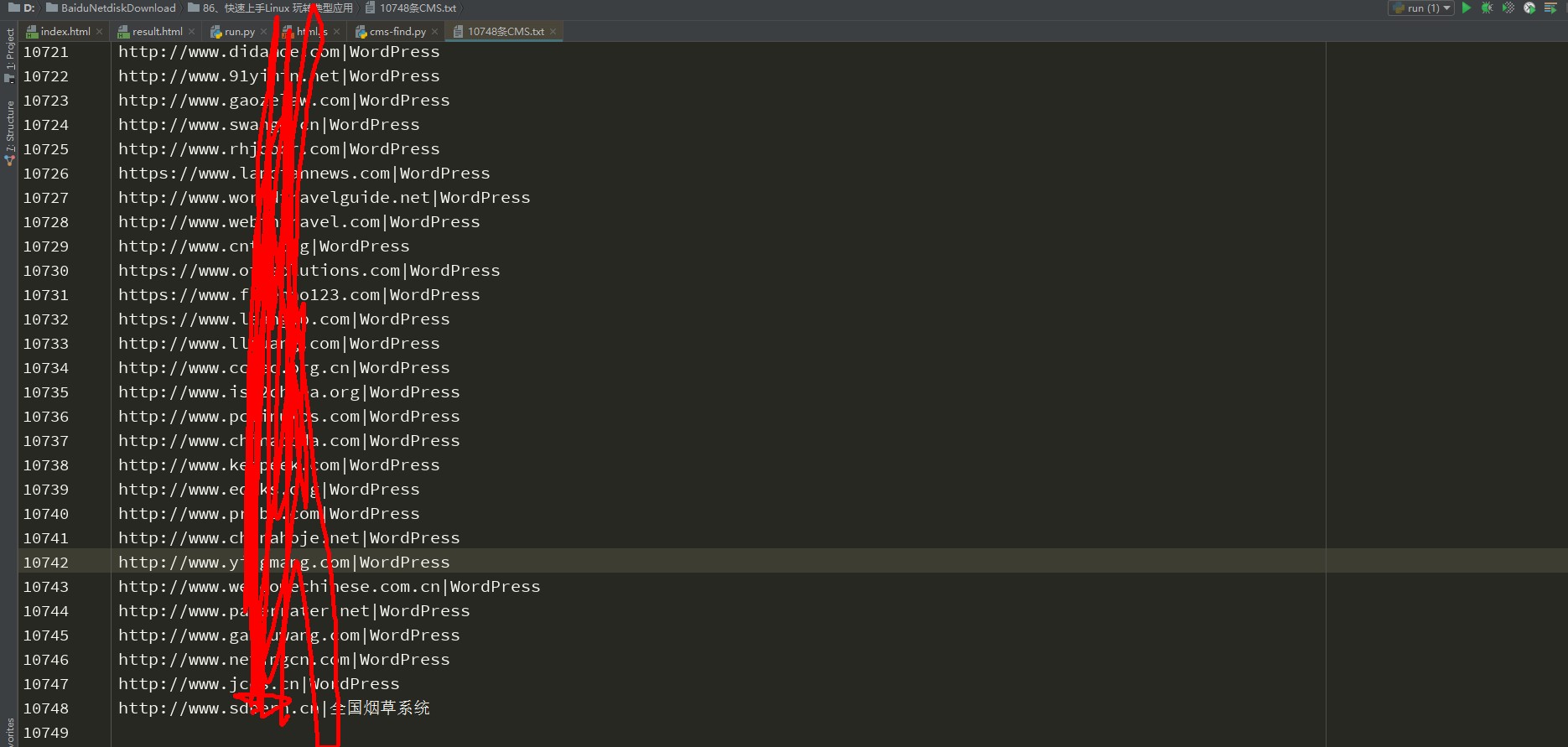
其实没啥技术含量,只是整理了一下CMS的指纹,基于Mysql和Python的知识上,添加了一些新的特性,性能提升了不少,对异步协程和数据库结构有了更加深的认识。
lang_cms_find 2.7
lang_cms_find2.7版本与3.5版本的区别在于3.5相当于精简的Yolanad扫描器,着力于无限URL采集+CMS识别,如果手里有一批URL网址,如何才能快速的把这批网址识别CMS,然后按照不同CMS类型保存在不同的文本中呢?这个时候2.7版本的优势就体现出来了,支持导入文本,识别规则采用的3.5版本相同的规则校验,按照识别出来的CMS按照种类保存在目录下。
导入自己采集好的网址,自动保存生成的结果如下:
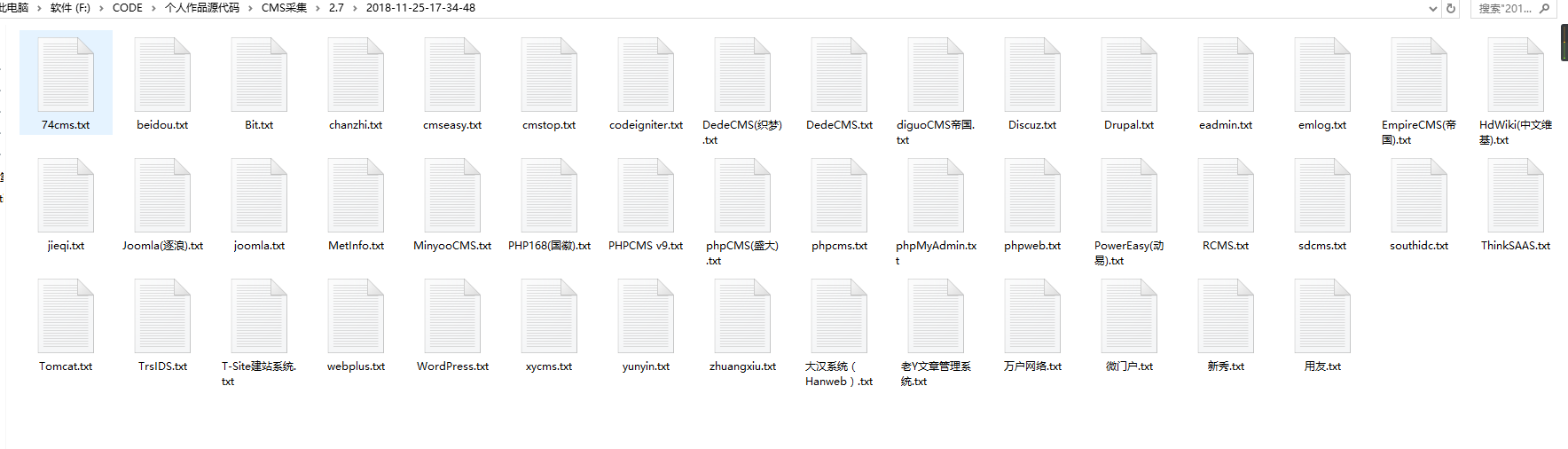
lang_cms_find 2.8
花了整整一天的时间重新整理指纹库,并且新增了许多指纹,目前指纹库数量为4498条指纹。
lang_cms_find 3.5
更高更快更强
程序暂时不放出去了,把运行了两个礼拜的结果分享一下吧
自动创建数据库,全面优化表索引接口优化查询,定时将数据库结果生成导出

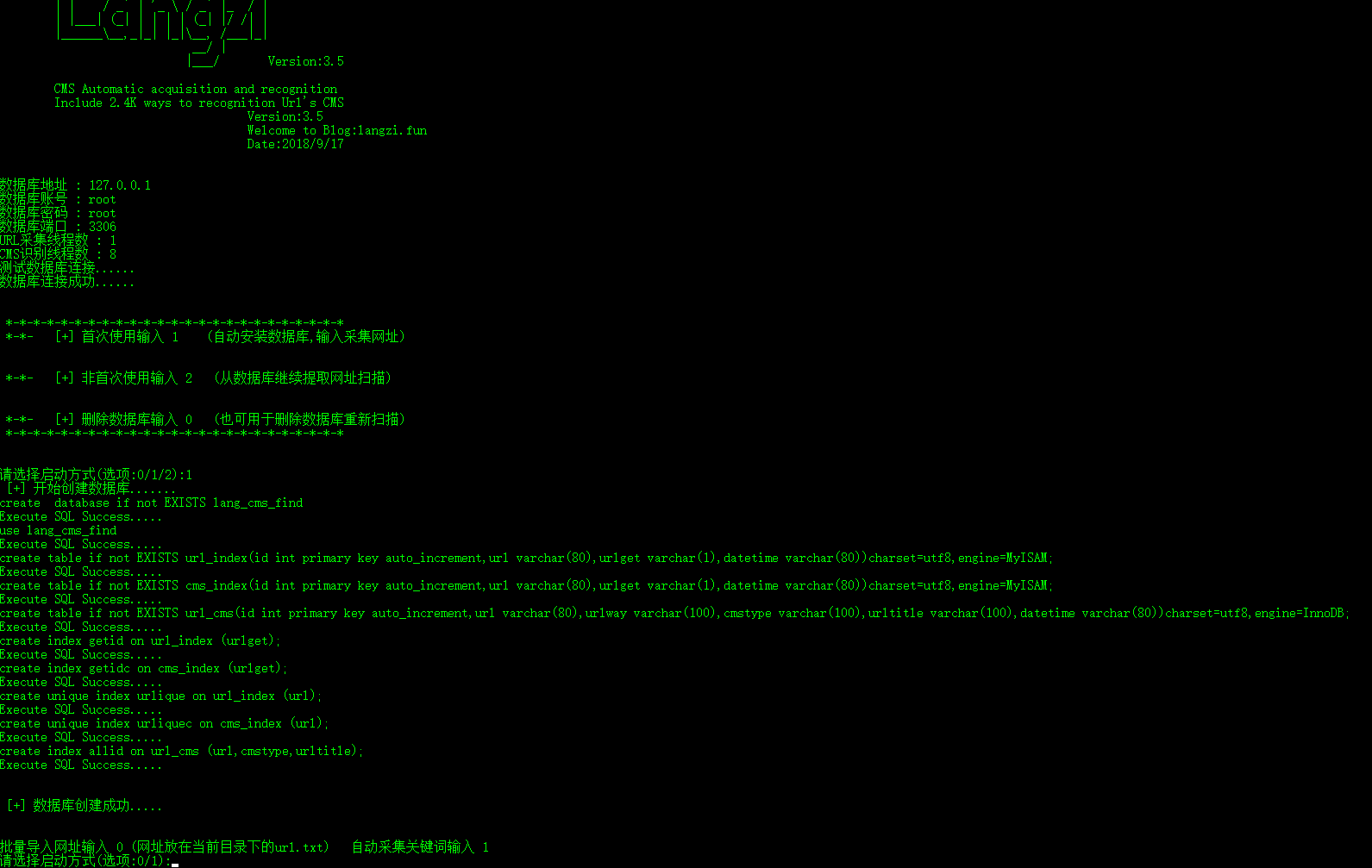

lang_cms_find 3.6
稍微整理指纹库信息
下载地址
upload 目录下 有个压缩包 密码是土司的域名

