所谓错过,不是错了,而是过了。
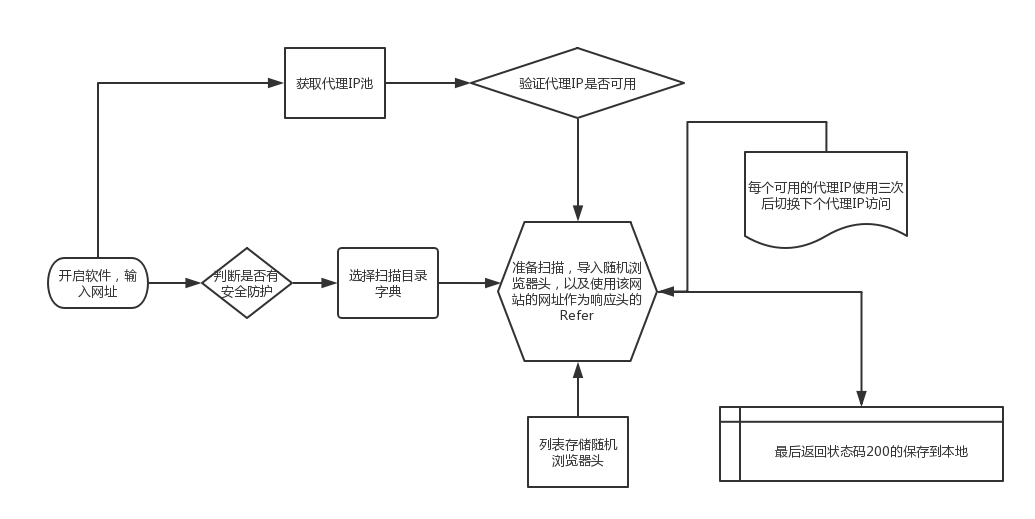
这篇文章好像上传到t00ls了,这里就懒得继续写了
代码如下:
# -*- coding: utf-8 -*-
# @Time : 2018/5/3 0003 10:52
# @Author : Langzi
# @Blog : www.langzi.fun
# @File : 生产者消费者.py
# @Software: PyCharm
import sys
import Queue
import time
import os
import requests
import re
import random
import threading
reload(sys)
sys.setdefaultencoding('utf-8')
url = str(raw_input(unicode('请输入网址:','utf-8').encode('gbk')))
url = url if 'http' in url else 'http://' + url
print '[-] Scan : ' + url
dir_=[x.decode('gbk').encode('utf-8') for x in os.listdir('./config')]
print unicode('[*] 请选择扫描目录(example:php.txt)')
print '---------------------'
for x in dir_:print x
print '---------------------'
dic_ = [url + x.replace('\n','') for x in open(str('./config/'+(raw_input('Set Dir:')))).readlines()]
print unicode('[+] 开启自动获取代理IP....','utf-8')
headerssx = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"]
q = Queue.Queue()
qq = Queue.Queue()
headerss={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'}
def get_ip(page):
url1='http://www.66ip.cn/mo.php?sxb=&tqsl=30&port=&export=&ktip=&sxa=&submit=%CC%E1++%C8%A1&textarea='
url2='http://www.xicidaili.com/nn/'
for i in range(1,page):
url1_1=url1+str(i)
url2_2=url2+str(i)
try:
r = requests.get(url=url1_1,headers=headerss,timeout=5)
rr = re.findall(' (.*?)<br />',r.content)
for x in rr:
#print x
q.put(x)
#time.sleep(20)
except Exception,e:
print e
try:
time.sleep(20)
r = requests.get(url=url2_2,headers=headerss,timeout=5)
rr = re.findall('/></td>(.*?)<a href',r.content,re.S)
for x in rr:
x1 = x.replace('\n','').replace('<td>','').replace("</td>",':').replace(' ','').replace(': ','')
#print x1
q.put(x1)
#time.sleep(20)
except Exception,e:
print e
def scan_ip():
for i in dic_:
qq.put(i)
while 1:
headers={
'Host':str(url.replace('http://','').replace('https://','')),
'User-Agent':'langzi chao ji shuai',
'Referer':str(url),
'Accept-Encoding':'gzip, deflate',
'Accept-Language':'zh-CN,zh;q=0.9'
}
UA = random.choice(headerssx)
headers['User-Agent']=UA
proxies={}
ip = q.get()
proxies['http'] = str(ip)
# proxies['http'] = 'http://'+str(ip)
# proxies['https'] = 'https://'+str(ip)
try:
req2 = requests.get(url='http://www.langzi.fun/robots.txt', proxies=proxies, headers=headerss, timeout=5)
if 'categories' in req2.content:
print str('[IP Scan '+time.strftime("%H:%M:%S", time.localtime()) + ']'+proxies['http']).ljust(60) + ' | ' + unicode('该代理可正常访问网页...','utf-8')
try:
u = qq.get()
req3 = requests.head(url=u,proxies=proxies,headers=headers,timeout=5)
print str('[DIR Scan '+time.strftime("%H:%M:%S", time.localtime()) + ']'+req3.url + ' ' + str(req3.status_code)).ljust(60) + ' | '+str(proxies['http'])
if req3.status_code == 200:
with open((str(url+'.txt')),'a+')as a:
a.write(u+'\n')
else:
pass
except:
print str('[DIR Scan '+time.strftime("%H:%M:%S", time.localtime()) + ']'+u).ljust(60) + ' | ' + unicode('扫描该目录出现代理异常,重回继续扫描| ','utf-8') + proxies['http']
qq.put(u)
else:
print str('[IP Scan '+time.strftime("%H:%M:%S", time.localtime()) + ']'+proxies['http']).ljust(60) + ' | ' + unicode('该代理无法访问网页...', 'utf-8')
except :
print str('[IP Scan '+time.strftime("%H:%M:%S", time.localtime()) + ']'+proxies['http']).ljust(60) + ' | ' +unicode('无法连接到代理服务器...','utf-8')
# for i in range(2):
# # 这里是要开2个任务量,就是2个线程
t = threading.Thread(target=get_ip,args=(100,)).start()
# 传入的参数是10,回归到get_ip函数,发现传入的参数就是要扫描提供代理网站的页数
t1 = threading.Thread(target=scan_ip).start()

