平时他蔫得就像一根干黄瓜,可一旦决定了要做什么,就会如一根泡了水的西芹那样精神无比。
最近有需求扫描备份文件和敏感文件,以及大量的漏洞模糊测试,需要对一个网站的目录获取更加详细的结构,小的网址可能不需要。需要测试就需要完整的目录结构,本次使用python开发针对url路径进行模糊测试,尽量挖掘到更多的信息和漏洞。
流程图如下
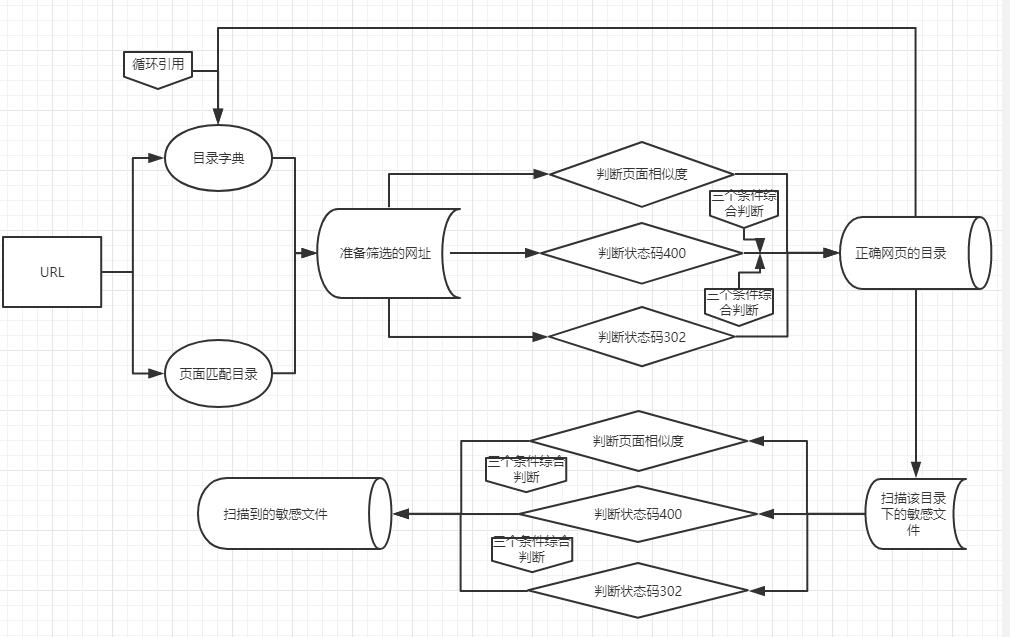
扫描步骤
- 首先爬取这个网页的所有目录,正则匹配出来
- 随后根据字典拼接url,与上面的网址进行去重
- 去重后的结果进行识别,检测是否是正确存在的网址
- 随后对第三步正确的网址目录筛选出来,进行扫描该目录下的敏感文件
- 同时对第三步正确的网址目录进行再度目录拼接
- 重复
上面流程没问题,但是第一步第二步有些累赘,倒不如第一步的时候直接匹配出网页里显示的目录后,把目录加入到第二步的字典当中。
关于匹配目录,其实这一步是比较复杂的。有一种情况就是:
1. 扫描www.langzi.fun
2. 在www.langzi.fun主页发现了一个zhhan的目录
3. 随即www.langzi.fun/zhhan目录下又有一个zzhhaa目录,那么添加到目录字典中的目录名为zhhan/zzhhzz/
4. 如果www.langzi.fun/zhhan/目录下有一个www.langzi.fun/zhhan/mian.php,访问这个php文件又发现一个www.langzi.fun/php/zhaonn/的目录,那么这个目录添加到字典的时候文件名是/php/zhaonn/,这就涉及到反复调用文件,相当于第四步的结果要去除文件名后提取出目录继续添加到字典。
5. 比如页面有一个www.langzi.fun/langzi.php,langzi.php的文件名langzi是字典中不可能存在的,所以对于文件猜测的后缀列表中应该加上langzi,然后检查langzi.zip是否存在,langzi.rar是否存在,langzi的目录是否存在。存在的话又继续添。
页面识别
页面识别功能的作用是:
筛选出状态码为200的正确的存在的页面
- 关于404的识别
用状态码和页面相似度来判断
状态码分为404 200 302
只要返回404或者302 就返回False
如果返回200 并且与404页面的相似度不大的话
就返回TRUE
获取404页面很简单啊,www.langzi.fun/aflajkhfwehfkjzx234这就是一个404页面
Python中数据相似度的判断有许多现成的库.
- difflib
- gensim
- Levenshtein
- fuzzywuzzy 地址
或者用相似度计算的方法来计算
- 相似度计算:用欧氏距离来计算。相似度用距离来衡量,距离越大,相似度越小;距离越小,相似度越大。
- 皮尔逊相关系数:这个参数用来度量两个向量之间的相似度。corroef()进行计算,皮尔逊相关系数取值从-1到+1,我们可以通过0.5+0.5*corrcoef()来计算,将值调整归一化到0到1之间。
- 余弦相似度:两个向量夹角的余弦值。夹角为90度,相似度为0,方向相同,相似度为1,方向相反,相似度为-1,取值范围也在-1到+1之间。因此,我们将它归一化到0到1之间。cos=AB/||A||||B||. 其中,||A|| ||B||表示2范数。利用linalg.norm().
如何判断是不是错误页面,nmask表哥使用方法是基于余弦相似度。
我一开始想法是基于jieba分词统计数据来判断相似性地址
后来懒癌发作,直接用内置库difflib来解决问题。
difflib使用方法
# -*- coding: utf-8 -*-
# @Time : 2018/8/8 0008 14:56
# @Author : Langzi
# @Blog : www.langzi.fun
# @File : 判断字符串相似度.py
# @Software: PyCharm
import difflib
import requests
url_0 = 'http://www.langzi.fun/56454'
url_1 = 'http://www.langzi.fun/admin/666'
url_2 = 'http://www.langzi.fun/'
def content(url):
return requests.get(url).content
url_0_ = content(url_0)
url_1_ = content(url_1)
url_2_ = content(url_2)
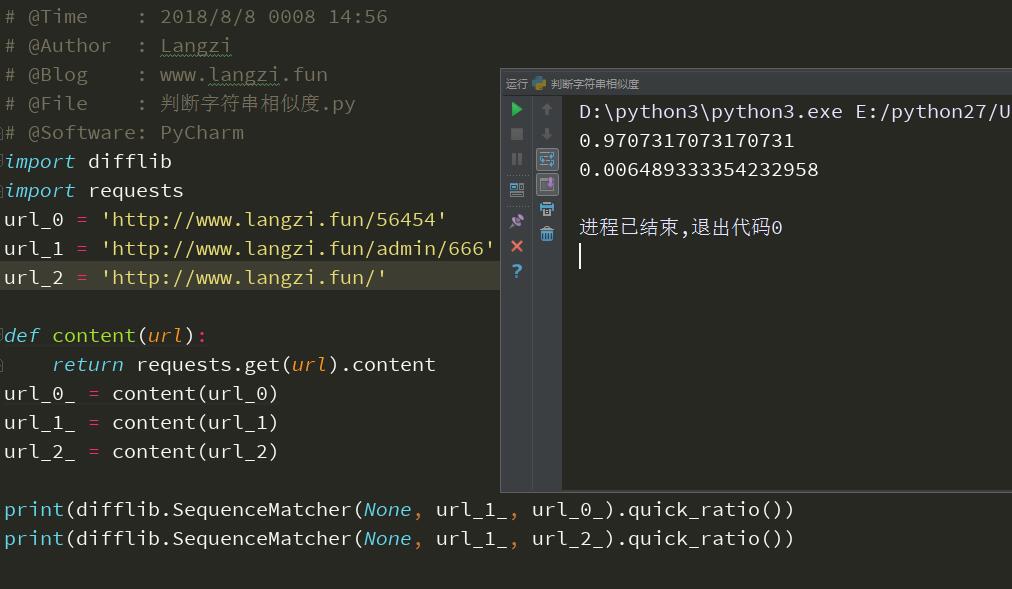
print(difflib.SequenceMatcher(None, url_1_, url_0_).quick_ratio())
print(difflib.SequenceMatcher(None, url_1_, url_2_).quick_ratio())
返回结果
0.9707317073170731
0.006489333354232958
其中url_0与url_1是错误的不存在的页面,url_2是正确的页面,可以看到他们的相似度。
这里借喻一下,url_0是我直接构造的404页面,url_1月url_2是我要扫描的网址,那么根据相似度就可以判断url_1与url_0相似度极大,所以url_1应该就是404页面了。
这里的代码是简写,详细扫描中除了异常处理还要禁止跳转。
字典准备
目录与文件
工欲善其事必先利其器,除了扫描功能之外,一份优秀的字典能帮助达成非常精确的扫描成功率,当然很明显我手里没有这么一份优秀的字典,在gayhub上翻了一点破字典下来。不要吝啬手里优秀的字典,独乐乐不如众乐乐发给我也让我爽一爽..嘻嘻
dir_dict.txt:目录字典
格式:
/
/admin_index
/down
/star
/book
/moban
/shipin
/tags
file_dict.txt:敏感文件
格式:
index
changepwd
down
star
book
admin
admin
aspadmin
adminl
admin_admin
Linkuploadupload
后缀名: ['.php','.asp','.aspx','.yml','.ini','.swp','.jsp','.do','.action','.sh','.html','.txt','.htm','.shtml','.xml','.json','.api','.config','.configs','.xmls']
这种文件目录的字典需要收集。
备份文件
备份文件的字典和上面的不一样
组合文件和目录的字典依赖动态页面生成,比之前单独的批量扫描备份多了无数种
对url进行分割拼接成字典有27种方式,后缀名有13种,固定的常见备份名有130种,常见的备份文件目录14种,再加上动态目录生成和目录字典拼接有100+。总结在一起相当于彻彻底底从头到尾给扫了一遍。
频率过高WAF检测
先留着
效果目标
能根据页面自动生成动态目录,动态文件检测。动态收集扫描目标相关信息后进行二次整理形成字典规则,利用动态规则的多线程敏感信息泄露检测,搭配优秀的字典不断重复扫描检测,真正实现滴水不漏的扫描,包括备份文件敏感信息,以及隐藏在最神秘深处的文件都给挖掘出来
资料 https://www.jianshu.com/p/937a89635a13
资料 http://zone.secevery.com/question/87
资料 https://blog.csdn.net/ZZZJX7/article/details/78252735
资料 https://github.com/ring04h/weakfilescan
资料 https://thief.one/2018/04/12/1/
资料 https://blog.csdn.net/weixin_42039090/article/details/80533505
资料 https://blog.csdn.net/qcyfred/article/details/74898179
资料 https://blog.csdn.net/u013055678/article/details/52695280
资料 https://blog.csdn.net/xiexf189/article/details/79092629
资料 https://blog.csdn.net/weixin_41667664/article/details/80079814
先留着,我要睡觉了

