“你说我虽然是个普通人,我也想人家关注我啊,我也想有女孩喜欢我啊,我也想有什么东西可以吹牛啊……总不能因为我没本事很普通,就当一辈子的路人甲吧?那有什么意思啊?可在家里我真的是什么都没有,”他摊了摊手,“什么都没有……我饿了,你有没有 什么吃的?”
阅读提要
全文约1.5W字,大致阅读完约15分钟,包含主要知识点:HTTP状态码,网页跳转方式,404错误页面种类,定制型网址404识别,通用型404页面识别,其中关键部位文字使用橙色重点标注,网址使用绿色重点标注。
目录:
- 状态码信息
- 页面跳转方式
- 404页面种类
- 针对单一网址404页面识别
- 针对通用型网址404页面识别
状态码
当浏览者访问一个网页时,浏览者的浏览器会向网页所在服务器发出请求。当浏览器接收并显示网页前,此网页所在的服务器会返回一个包含HTTP状态码的信息头(server header)用以响应浏览器的请求。
HTTP状态码的英文为HTTP Status Code。
下面是常见的HTTP状态码:
200 - 请求成功
301 - 资源(网页等)被永久转移到其它URL
404 - 请求的资源(网页等)不存在
500 - 内部服务器错误

状态码都会在请求头中显示,本文中重点探讨在渗透测试的信息收集中对网址进行扫描中遇到的404页面自动识别的解决方案。
页面跳转
当访问一个不存在的网页时,默认会进行自动跳转到其他网页或者返回不存在页面,按照经验URL跳转方式可以分成两种,第一种是服务端设置好后的客户端跳转,第二种是经过服务端处理后进行的跳转。
如果是客户端跳转,假设后端程序员不对源码进行修改的话,默认返回的状态码是301或者302,然后由经过设置好的规则开始跳转到下一个页面,这种方式使用代码识别比较简单。

服务端跳转,是由服务器进行处理结请求后,服务端发现页面不存在,但是还是给你返回200状态码然后给你跳转到正常页面,将结果从后端发送给前端,获取的状态码是200,该种方式使用代码进行识别难度稍大。
如果网页不存在,则会自动返回404状态码和相关错误界面。
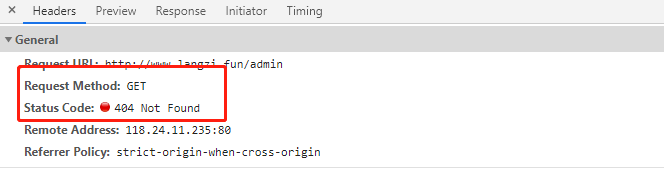
404页面种类
URL的404页面的识别,按照经验有如下几种情况
- 直接返回错误页面,请求头中显示404状态码
- 将错误页面重定向到一个新的页面,重定向方式是上面说的两种,请求头中显示301,302状态码。
- 程序员在后端代码中,将错误页面的状态码设置成200的错误页面,然后直接返回到前端,请求头状态码为200.
- 程序员在后端代码中,将错误页面的请求直接从后端重定向到首页,同上。
常见的情况大概这么多,尝试使用python实现对404页面的检测识别,这里还可以分成两类代码,第一类是通用型的,即可以对不同的网址识别404页面,通用性大更加方便,同时难度和容错率也相对提高。第二种则是专门对某个网址进行单独的检测,这种定制化的相对简单,首先分析该网站的返回状态码,返回的错误页面,是否跳转信息,就可以判断是否为404页面。
定制型404页面识别
识别404分通用型与制定型,制定型即制定一个网站进行目录扫描,单独写一个文件。这个比较容易,但是这里存在一个问题,即你扫描网站的目录结果还是扫描网站的文件,如果扫描网站的文件,那么适用上面的规则,如果是扫描网站的目录结构,那么会误杀许多请求,比如很多网站的后台管理地址为
localhost/admin/admin.php
当你请求如下链接的时候
local/admin
这个时候会自动跳转到
localhost/admin/admin.php

但是如果适用上面的规则就会造成一定的错误率。解决办法则是不检测状态码但是进行关键词识别,即如果请求链接,链接网页的内容出现关键词比如【管理员登录,后台管理】这些字样,则直接保存结果。
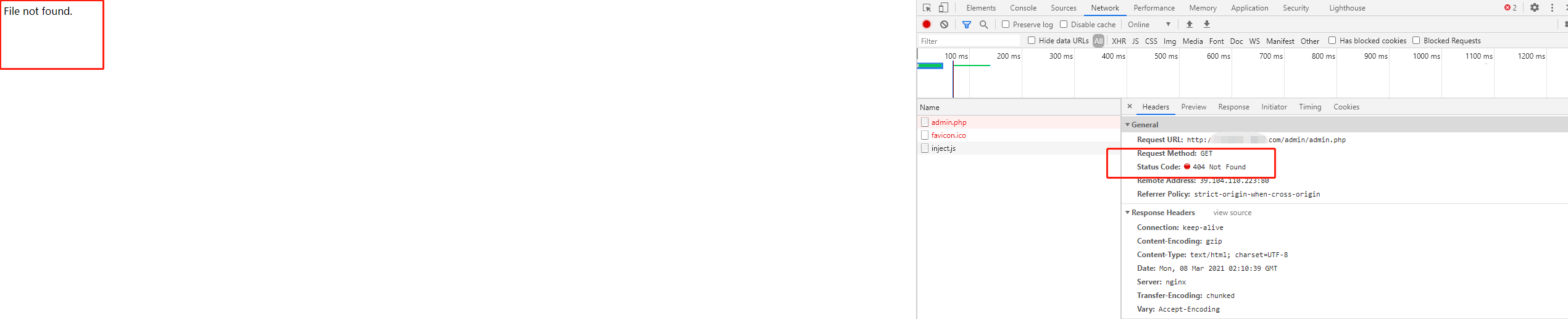
还有就是额外分析网页的HTTP请求流程,访问错误的网页,查看状态码,错误信息,是否跳转,页面出现的错误关键词,如果出现WAF还可以加上代理IP并且延迟访问绕过WAF,相对这里不做展开讨论。
通用型404页面识别
抛开定制型的404页面识别,还有许多别的方法比如排除法,即进行一定的规则检测,比如判断状态码并且进行跳转页面相似度检测。
检测方法
按照常见情况可以分出下面两种简单的检测方式:
第一种方法这里判断条件为:
1. requests参数设置allow_redirects=False
2. 首先进行状态码检测 只检测如果状态码 404,则立即抛出错误
上面一种是新手很常见的用法,速度快但是会存在误报情况,第二种方法判断条件:
1. requests参数设置allow_redirects=True
1. 获取网站首页的内容 保存为 Content_1 固定变量,用来做相似度判读
2. 获取错误页面的内容 保存为 Content_2,状态码 保存为 Status_2 固定变量,用来做相似度判读
3. 获取检测目录的内容 保存为 Content_3,状态码 保存为 Status_3
4. 如果固定变量 Status_2 == Status_3 == 404, 直接抛出错误,省下 检测相似度的时间
5. 如果上面没有异常出现 则对 Content_3 与Content_1 和 Content_2 进行相似度判读
6. 如果相似度超过制定的阈值,则直接触发错误,判读为404页面
思维流程
对一个网站的目录获取更加详细的结构,小的网址可能不需要。需要测试就需要完整的目录结构,本次使用python开发针对url路径进行模糊测试,尽量挖掘到更多的信息和漏洞。
流程图如下
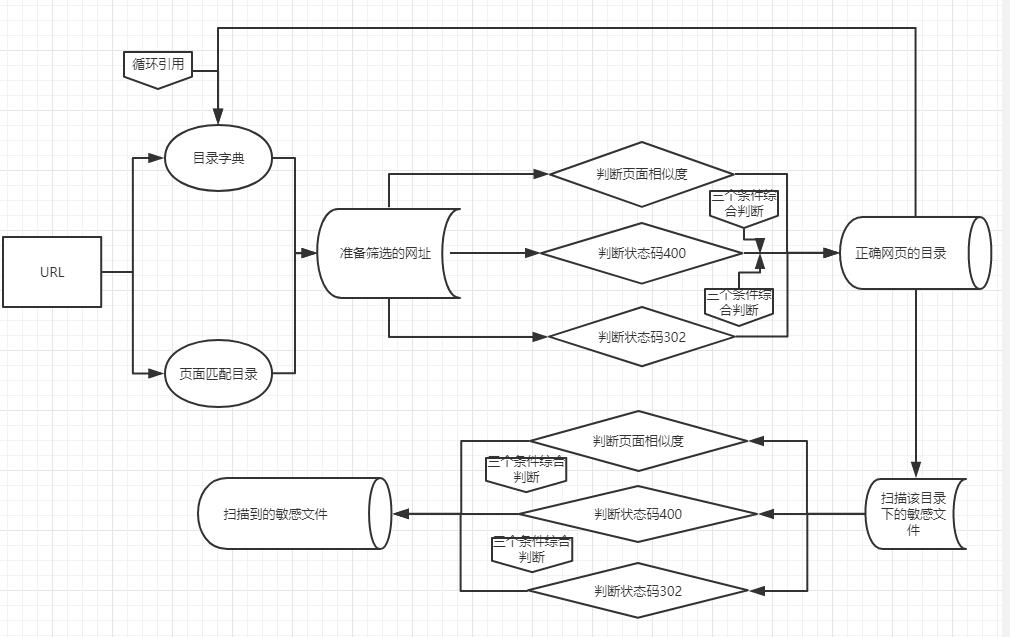
功能拆分
页面识别功能的作用是:
筛选出状态码为200的正确的存在的页面
- 关于404的识别
用状态码和页面相似度来判断
状态码分为404 200 302
只要返回404或者302 就返回False
如果返回200 并且与404页面的相似度不大的话
就返回TRUE
获取404页面很简单啊,www.langzi.fun/aflajkhfwehfkjzx234这就是一个404页面
Python中数据相似度的判断有许多现成的库.
- difflib
- gensim
- Levenshtein
- fuzzywuzzy 地址
或者用相似度计算的方法来计算
- 相似度计算:用欧氏距离来计算。相似度用距离来衡量,距离越大,相似度越小;距离越小,相似度越大。
- 皮尔逊相关系数:这个参数用来度量两个向量之间的相似度。corroef()进行计算,皮尔逊相关系数取值从-1到+1,我们可以通过0.5+0.5*corrcoef()来计算,将值调整归一化到0到1之间。
- 余弦相似度:两个向量夹角的余弦值。夹角为90度,相似度为0,方向相同,相似度为1,方向相反,相似度为-1,取值范围也在-1到+1之间。因此,我们将它归一化到0到1之间。cos=AB/||A||||B||. 其中,||A|| ||B||表示2范数。利用linalg.norm().
如何判断是不是错误页面,nmask表哥使用方法是基于余弦相似度。
我一开始想法是基于jieba分词统计数据来判断相似性地址
后来懒癌发作,直接用内置库difflib来解决问题。
difflib使用方法
# -*- coding: utf-8 -*-
# @Time : 2018/8/8 0008 14:56
# @Author : Langzi
# @Blog : www.langzi.fun
# @File : 判断字符串相似度.py
# @Software: PyCharm
import difflib
import requests
url_0 = 'http://www.langzi.fun/56454'
url_1 = 'http://www.langzi.fun/admin/666'
url_2 = 'http://www.langzi.fun/'
def content(url):
return requests.get(url).content
url_0_ = content(url_0)
url_1_ = content(url_1)
url_2_ = content(url_2)
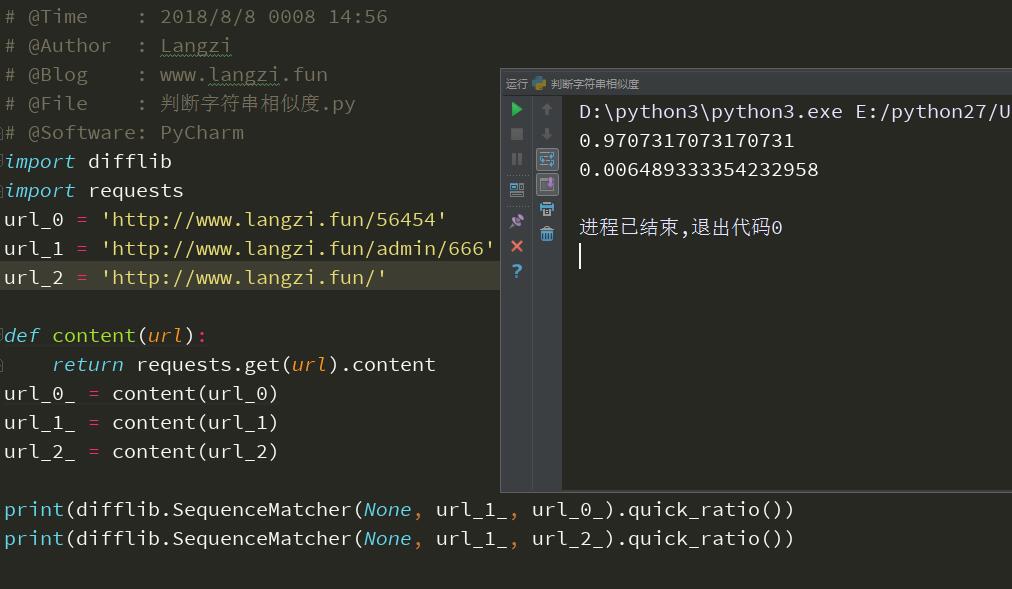
print(difflib.SequenceMatcher(None, url_1_, url_0_).quick_ratio())
print(difflib.SequenceMatcher(None, url_1_, url_2_).quick_ratio())
返回结果
0.9707317073170731
0.006489333354232958
其中url_0与url_1是错误的不存在的页面,url_2是正确的页面,可以看到他们的相似度。
这里借喻一下,url_0是我直接构造的404页面,url_1与url_2是我要扫描的网址,那么根据相似度就可以判断url_1与url_0相似度极大,所以url_1应该就是404页面了。
这里的代码是简写,详细扫描中除了异常处理还要禁止跳转。
优化代码
构建了一下代码工程
# coding:utf-8
import requests
requests.packages.urllib3.disable_warnings()
import difflib
Dir_Path = ['/admin', '/login', '/manage', '/log_home', '/admin.php', '/categories/']
def Return_Http_Content(url):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
r = requests.get(url, headers=headers, verify=False, timeout=5)
encoding = 'utf-8'
try:
encoding = requests.utils.get_encodings_from_content(r.text)[0]
except:
pass
content = r.content.decode(encoding, 'replace')
return (content, r.status_code)
except Exception as e:
return ('langzi', 404)
def Return_Content_Difflib(original, compare):
res = (str(difflib.SequenceMatcher(None, original, compare).quick_ratio())[2:6])
if res == '0':
res = 0
return res
else:
res = res.lstrip('0')
return int(res)
# return 4 integer like 1293 or 9218
class Check_Page_404:
def __new__(cls, url):
cls.url_200 = Return_Http_Content(url)
cls.url_404 = Return_Http_Content(url.rstrip('/') + '/langzi.html')
return object.__new__(cls)
def __init__(self, url):
self.url = url
def Check_404(self, suffix):
chekc_url = Return_Http_Content(self.url.rstrip('/') + suffix)
if chekc_url[1] == 404:
return False
Dif_1 = Return_Content_Difflib(chekc_url[0], self.url_200[0])
Dif_2 = Return_Content_Difflib(chekc_url[0], self.url_404[0])
if Dif_1 > 6000 and Dif_2 < 8000:
# 注意这里是最重要的调参
# 判断是否为错误页面主要取决与这个调整至
# 调整范围为1-10000
# 按照不同页面调试出最优的参数
return True
else:
return False
if __name__ == '__main__':
url = 'http://www.langzi.fun'
test = Check_Page_404(url.strip('/'))
for suffix in Dir_Path:
print('Check Url : ' + url.strip('/') + suffix)
print(test.Check_404(suffix=suffix))
如果正确存在网页,则会返回True
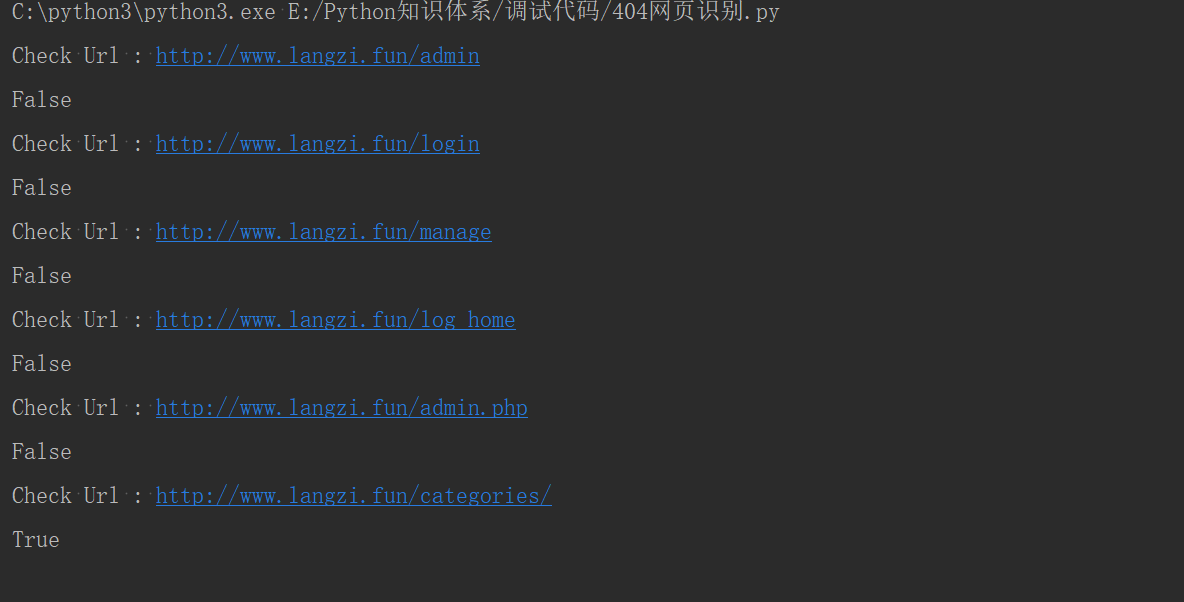
封装后,使用方法如下
url = 'http://www.langzi.fun'
# 扫描目标
Dir_Path=['/admin','/login','/manage','/log_home','/admin.php','/categories/']
# 目录字典
Check = Check_Page_404(url)
# 实例化对象
for suffix in Dir_Path:
# 对字典进行遍历
if Check.Check_404(suffix=suffix):
print('Url is Alive : '+ url + suffix)
如此只有正确存在的网页才会返回
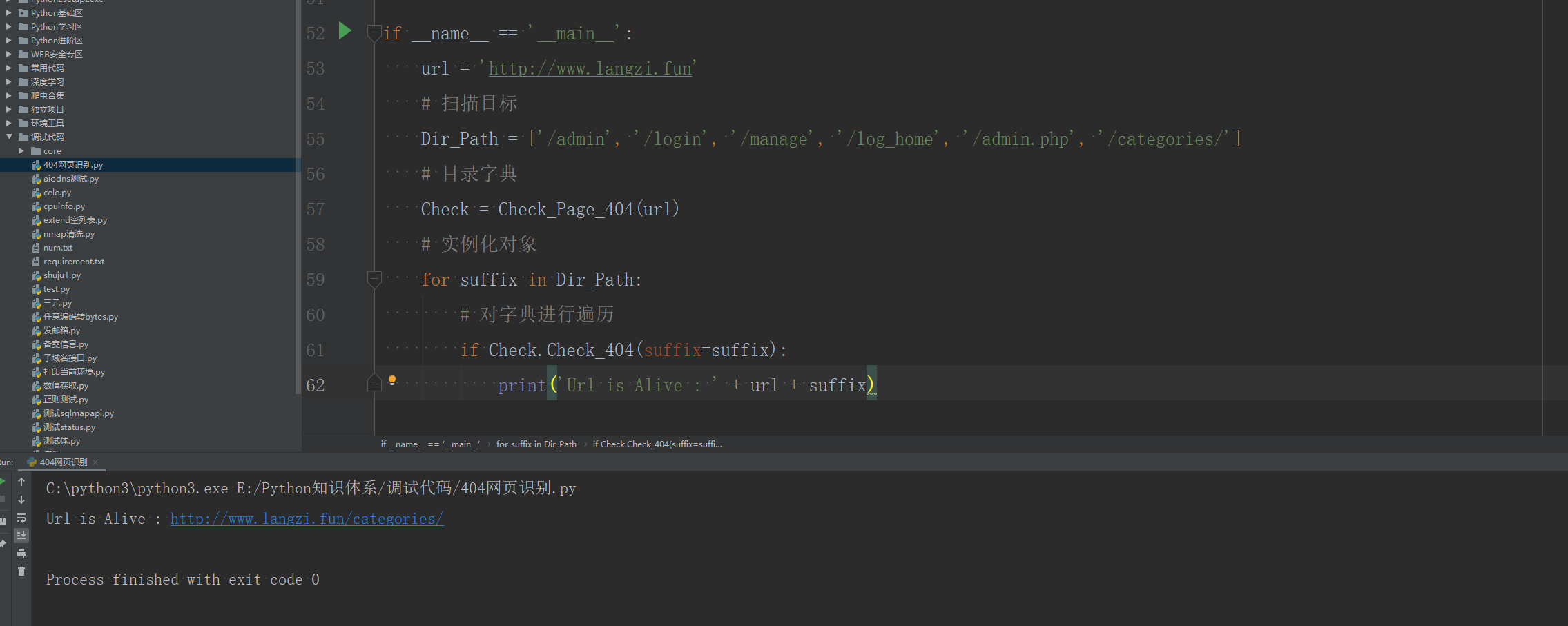
补充
光是靠调整相似度的参数来判断的依据其实并不准确,因为不同网页返回的错误页面与正确页面的差距有些大有些小,所以还可以额外加入关键词判断,比如网页中出现了如下关键词就判定网页为404错误页面

调整后代码为:
# coding:utf-8
import requests
requests.packages.urllib3.disable_warnings()
import difflib
Dir_Path = ['/blog/','/admin', '/login', '/manage', '/log_home', '/admin.php', '/categories/']
Black_Con = ['404 - Not Found','抱歉!页面无法访问','网址已失效','404 Not Found','403 Forbidden',' 秒后跳转至','页面不存在','页面没有找到','检查您输入的网址是否正确']
def Return_Http_Content(url):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
r = requests.get(url, headers=headers, verify=False, timeout=5)
encoding = 'utf-8'
try:
encoding = requests.utils.get_encodings_from_content(r.text)[0]
except:
pass
content = r.content.decode(encoding, 'replace')
for b in Black_Con:
if b in content:
print('页面中存在错误信息关键词')
return ('langzi', 404)
return (content, r.status_code)
except Exception as e:
return ('langzi', 404)
def Return_Content_Difflib(original, compare):
res = (str(difflib.SequenceMatcher(None, original, compare).quick_ratio())[2:6])
if res == '0':
res = 0
return res
else:
res = res.lstrip('0')
return int(res)
# return 4 integer like 1293 or 9218
class Check_Page_404:
def __new__(cls, url):
cls.url_200 = Return_Http_Content(url)
cls.url_404 = Return_Http_Content(url.rstrip('/') + '/langzi.html')
return object.__new__(cls)
def __init__(self, url):
self.url = url
def Check_404(self, suffix):
chekc_url = Return_Http_Content(self.url.rstrip('/') + suffix)
if chekc_url[1] == 404:
return False
Dif_1 = Return_Content_Difflib(chekc_url[0], self.url_200[0])
Dif_2 = Return_Content_Difflib(chekc_url[0], self.url_404[0])
print(Dif_1,Dif_2)
if Dif_1 > 6000 and Dif_2 < 8000:
# 注意这里是最重要的调参
# 判断是否为错误页面主要取决与这个调整至
# 调整范围为1-10000
# 按照不同页面调试出最优的参数
return True
else:
return False
if __name__ == '__main__':
url = 'https://www.langzi.fun'
test = Check_Page_404(url.strip('/'))
for suffix in Dir_Path:
print('Check Url : ' + url.strip('/') + suffix)
print(test.Check_404(suffix=suffix))
以前都是个人一点拙略的想法,通用率不是很完善,希望能起到抛砖引玉的作用,给大家提供一些思路上的帮助。

