这个世界有多大,取决于你认识多少人,你每认识一个人,世界对你来说就会变大一些。真正属于你的世界其实是很小的,只有你去过的地方吃过的东西看过的落日,还有会在乎你死活的朋友。
设计流程
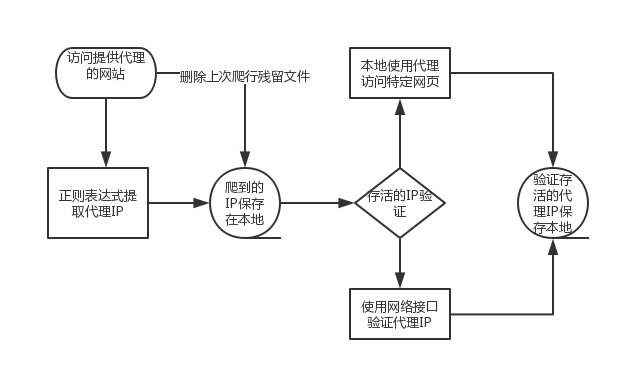
采集接口
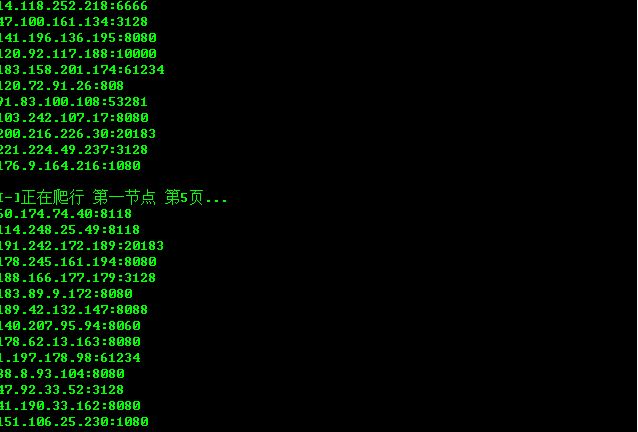
寻找了3个提供免费代理IP的网站,用正则扣下这些网站提供的代理IP。
代理IP存活验证
本地访问验证
requests库中有proxies这个功能,把代理IP填写进去,然后访问我的CSDN博客,如果访问成功就保存在本地的result.txt文本中。
使用网络接口
在这个网址发送请求,根据回显的内容判断是否存活。存活的IP保存在本地的result.txt文本,网络接口加本地双重验证。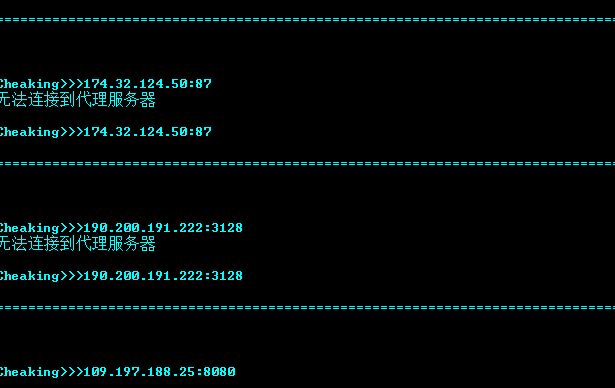
下载地址
链接:https://pan.baidu.com/s/1uGruRyC6fcfk1KZxo9JScg 密码:e65h
2019年3月22日 更新
因为最近需要到代理ip做爬虫,于是重写了一份,速度还可以哈,就是免费代理ip的寿命很短,有的能用五六分钟,有的只能用几十秒。
下载地址下载地址
代码
# -*- coding:utf-8 -*-
import queue
import requests
import re
import random
import time
import threading
import os
def headerss():
REFERERS = [
"https://www.baidu.com",
"http://www.baidu.com",
"https://www.google.com.hk",
"http://www.so.com",
"http://www.sogou.com",
"http://www.soso.com",
"http://www.bing.com",
]
headerss = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"]
headers = {
'User-Agent': random.choice(headerss),
'Accept': 'Accept:text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Cache-Control': 'max-age=0',
'referer': random.choice(REFERERS),
'Accept-Charset': 'GBK,utf-8;q=0.7,*;q=0.3',
}
return headers
q = queue.Queue()
def get_ip(page):
url1='http://www.66ip.cn/mo.php?sxb=&tqsl=30&port=&export=&ktip=&sxa=&submit=%CC%E1++%C8%A1&textarea='
url2='http://www.xicidaili.com/nn/'
for i in range(1,page):
headers = headerss()
url1_1=url1+str(i)
url2_2=url2+str(i)
try:
r = requests.get(url=url1_1,headers=headers,timeout=5)
encoding = requests.utils.get_encodings_from_content(r.text)[0]
res = r.content.decode(encoding, 'replace')
rr = re.findall(' (.*?)<br />',res)
for x in rr:
#print('抓到IP:{}'.format(x))
q.put(x)
except Exception as e:
#print(e)
pass
try:
time.sleep(20)
r = requests.get(url=url2_2,headers=headers,timeout=5)
rr = re.findall('/></td>(.*?)<a href',res,re.S)
for x in rr:
x1 = x.replace('\n','').replace('<td>','').replace("</td>",':').replace(' ','').replace(': ','')
#print('抓到IP:{}'.format(x1))
q.put(x1)
except Exception as e:
#print(e)
pass
def scan_ip():
while 1:
proxies={}
ip = q.get()
proxies['http'] = str(ip)
headers = headerss()
try:
url = 'http://www.baidu.com'
req2 = requests.get(url=url, proxies=proxies, headers=headers, timeout=5)
if '百度一下,你就知道' in req2.content.decode():
print('访问网址:{} 代理IP:{} 访问成功'.format(url,ip))
with open('result_ip.txt','a+')as a:
a.write(ip+'\n')
except Exception as e:
pass
if __name__ == '__main__':
try:
os.remove('result.txt')
except:
pass
print('''
_ _
| | (_)
| | __ _ _ __ __ _ _____
| | / _` | '_ \ / _` |_ / |
| |___| (_| | | | | (_| |/ /| |
|______\__,_|_| |_|\__, /___|_|
__/ |
|___/
批量获取代理IP
自动保存到文本
2019-3-22-21-30
''')
time.sleep(3)
threading.Thread(target=get_ip,args=(200,)).start()
for i in range(10):
threading.Thread(target=scan_ip).start()
2019-11-05 再次更新
简单的IP池
# -*- coding:utf-8 -*-
import requests,re,random,time,datetime,threading,queue
IP_66_headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh,zh-CN;q=0.9,en-US;q=0.8,en;q=0.7',
'Connection': 'keep-alive',
'Cookie': '__jsluid_h=d26e11a062ae566f576fd73c1cd582be; __jsl_clearance=1563459072.346|0|lMwNkWbcOEZhV8NGTNIpXgDvE8U%3D',
'Host': 'www.66ip.cn',
'Referer': 'http://www.66ip.cn/mo.php?sxb=&tqsl=30&port=&export=&ktip=&sxa=&submit=%CC%E1++%C8%A1&textarea=2',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'
}
IP_XC_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh,zh-CN;q=0.9,en-US;q=0.8,en;q=0.7',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Cookie': '_free_proxy_session=BAh7B0kiD3Nlc3Npb25faWQGOgZFVEkiJTBmOWM5NDc1OWY4NjljM2ZjMzU3OTM1MGMxOTEwMjNhBjsAVEkiEF9jc3JmX3Rva2VuBjsARkkiMWVGT0Z1dVpKUXdTMVFEN1JHTnJ3VVhYS05WWlIzUlFEcncvM1daVER2blk9BjsARg%3D%3D--66057a30315f0a34734318d2e6963e608017f79e; Hm_lvt_0cf76c77469e965d2957f0553e6ecf59=1563458856; Hm_lpvt_0cf76c77469e965d2957f0553e6ecf59=1563460669',
'Host': 'www.xicidaili.com',
'If-None-Match': 'W/"b7acf7140e4247040788777914f600e1"',
'Referer': 'http://www.66ip.cn/mo.php?sxb=&tqsl=30&port=&export=&ktip=&sxa=&submit=%CC%E1++%C8%A1&textarea=2',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'
}
IP_89_HEADERS = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8', 'Accept-Encoding': 'gzip, deflate', 'Accept-Language': 'zh,zh-CN;q=0.9,en-US;q=0.8,en;q=0.7', 'Cache-Control': 'max-age=0', 'Connection': 'keep-alive', 'Cookie': 'yd_cookie=325275f9-21df-4b82a1658307a42df71b5943b40f8aa57b86; Hm_lvt_f9e56acddd5155c92b9b5499ff966848=1572920966; Hm_lpvt_f9e56acddd5155c92b9b5499ff966848=1572922039', 'Host': 'www.89ip.cn', 'Upgrade-Insecure-Requests': '1', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
IP_66_URL = 'http://www.66ip.cn/mo.php?sxb=&tqsl=30&port=&export=&ktip=&sxa=&submit=%CC%E1++%C8%A1&textarea='
IP_XC_URL = 'http://www.xicidaili.com/nn/'
IP_89_URL = 'http://www.89ip.cn/index_{}.html'
ProducerIp = queue.Queue()
ConsumerIp = queue.Queue()
filename = (str(datetime.datetime.now()).replace(' ','-').replace(':','-').split('.')[0])+'AliveProxyIP.txt'
def GetUrlContent(url,headers):
try:
r = requests.get(url,headers=headers,timeout=20)
return r.content
except:
return None
def GetProxyIp():
while 1:
for i in range(1,50):
content = GetUrlContent(IP_89_URL.format(i),IP_89_HEADERS)
if content != None:
try:
content = content.decode()
ips = [':'.join(x) for x in re.findall('<td>\n\t\t\t(\d.*?)\t\t</td>\n\t\t<td>\n\t\t\t(\d.*?)\t\t</td>', content)]
for ip in ips:
ProducerIp.put(ip)
except Exception as e:
pass
content = GetUrlContent(IP_66_URL+str(i),IP_66_headers)
if content != None:
try:
ips = re.findall(b'\t(\d.*?:\d.*\d)<br />',content)
for ip in ips:
ProducerIp.put(ip.decode())
except:
pass
content = GetUrlContent(IP_XC_URL+str(i),IP_XC_HEADERS)
if content:
try:
ips = re.findall(b'<td>(\d.*\.\d.*)</td>\n.*?<td>(\d.*)</td>\n', content)
for i in ips:
ip = (i[0].decode() + ':' + i[1].decode())
ProducerIp.put(ip)
except:
pass
def CheckProxyIp():
while 1:
proxies={}
ip = ProducerIp.get()
# 获取得到的代理IP
proxies['http'] = str(ip)
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
try:
url = 'https://www.baidu.com'
req2 = requests.get(url=url, proxies=proxies, headers=headers, timeout=5)
if req2.status_code == 200 and '百度一下'.encode() in req2.content:
# print('[ {} ] 发现存活代理IP : {} '.format(str(datetime.datetime.now()).replace(' ','-').replace(':','-').split('.')[0] ,ip))
with open(filename, 'a+', encoding='utf-8')as a:
a.write(proxies['http'] + '\n')
ConsumerIp.put(proxies['http'])
except Exception as e:
#print(e)
pass
def Run():
threading.Thread(target=GetProxyIp).start()
for i in range(10):
threading.Thread(target=CheckProxyIp).start()
if __name__ == '__main__':
Run()

