真是这样的话,有些话,只有准确的时间准确的地点亲口说出来。现在时间错过了,再说也没用了
Langzi_安全巡航_0.95_原型机版本
Langzi_安全巡航_0.95_优化版
修复众多BUG
优化许多功能


跨年礼物~
Langzi_安全巡航_0.97版本
整体漏洞报告页面
首页需要包含的内容
网址:url
标题:title
漏洞概述:1,2,3,4,5,6(sql注入,敏感文件泄露,未授权访问等等)
发现时间:time
危害等级:高危
详情页面
漏洞网址:vlun url
漏洞描述:description
漏洞成因:cause
漏洞危害:risk
漏洞修复:repair
详情页面可以利用模板把网址传入即可,其他的固定模板结构,按照漏洞的传入不断地写入报告中,大致的样式如下:
xxxx网站漏洞信息报告【一级标题】
网址:www.langzi.fun
标题:浪子网络安全开发
漏洞概述:XSS漏洞,敏感信息泄露,数据库未授权访问
发现时间:2018年12月5日14:15:29
危害等级:高
然后是每个漏洞的具体详情解读
XSS漏洞【二级标题】
漏洞网址:http://app.langzi.fun.com/?area=%B5%D8%C7%F8&keyword=%C7%B0%B6%CB
提交方式:GET
漏洞参数:activityId
攻击载荷:"><img src=x onerror=prompt(1)>
漏洞种类:反射型XSS漏洞
漏洞成因:网站本身设计不严谨,导致执行用户提交的恶意js脚本,对网站自身造成危害。xss漏洞是web渗透测试中最常见而又使用最灵活的一个漏洞。它允许恶意用户将代码注入到网页上,其他用户在观看网页时就会受到影响。
漏洞危害:
1 cookie劫持(窃取cookie, 因为cookie能够代表用户的身份,所以盗取了cookie之后,就可以伪造用户去做一些事情了,这个产生的危害是非常可怕的。)
2 钓鱼,利用xss构造出一个登录框,骗取用户账户密码。
3 Xss蠕虫(利用xss漏洞进行传播)
4 修改网页代码
5 利用网站重定向
漏洞修复:
1 用户名、邮箱等表单验证(前台/服务器二次验证)
2 富文本使用白名单机制等
3 设置 cookie 时加入 HttpOnly 可使 js 脚本无法获取 cookie
4 定义允许的资源加载地址,比如图片 / 视频 / JS 脚本等
5 HTTPS加密访问
敏感信息泄露【二级标题】
漏洞网址:http://www.langzi.fun/langzi.rar:360M
漏洞描述:敏感信息泄露,
漏洞成因:
1 网站自动备份,备份文件名和路径容易被猜解。
2 管理员手动备份文件名,用的域名作为备份文件名称,并且放置在根目录。
漏洞危害:
1 网站存在备份文件:网站存在备份文件,例如数据库备份文件、网站源码备份文件等,攻击者利用该信息可以更容易得到网站权限,导致网站被黑。
2 敏感文件泄露是高危漏洞之一,敏感文件包括数据库配置信息,网站后台路径,物理路径泄露等,此漏洞可以帮助攻击者进一步攻击,敞开系统的大门。
3 由于目标备份文件较大,可能存在更多敏感数据泄露
4 该备份文件被下载后,可以被用来做代码审计,进而造成更大的危害
5 该信息泄露会暴露服务器的敏感信息,使攻击者能够通过泄露的信息进行进一步入侵。
6 当然 , 一般网站都会涉及到数据库操作 , 而一般来说 , 需要链接数据库就需要用户名/密码/端口/库名等信息 , 而这些信息肯定会在网站后台的源码里面又体现 , 因此这种情况是极其危险的 , 还有 , 一旦服务器开放了数据库的远程连接功能 , 攻击者就可以利用从源码中找到的数据库用户名和密码对远程数据库进行登陆 , 危险性不言而喻
漏洞修复:删掉备份文件或者重命名备份文件名。
.......
备份文件敏感信息泄露
生成字典的格式,分别有svn,git,webinfo,备份
模板需要参数:漏洞网址
扫描验证返回结果:字符串结果,备份扫描返回列表
svn 模板
扫描结果返回的参数只需要获取url即可,然后套嵌入模板即可
{
Url:http://www.langzi.fun/.svn,
Description:敏感信息泄露,
Cause:SVN(subversion)是源代码版本管理软件,造成SVN源代码漏洞的主要原因是管理员操作不规范。“在使用SVN管理本地代码过程中,会自动生成一个名为.svn的隐藏文件夹,其中包含重要的源代码信息。但一些网站管理员在发布代码时,不愿意使用‘导出’功能,而是直接复制代码文件夹到WEB服务器上,这就使.svn隐藏文件夹被暴露于外网环境,黑客可以借助其中包含的用于版本信息追踪的‘entries’文件,逐步摸清站点结构。”(可以利用.svn/entries文件,获取到服务器源码、svn服务器账号密码等信息),
Risk:
1 SVN产生的.svn目录下还包含了以.svn-base结尾的源代码文件副本(低版本SVN具体路径为text-base目录,高版本SVN为pristine目录),如果服务器没有对此类后缀做解析,黑客则可以直接获得文件源代码。
2 可以列出网站目录,甚至下载整站。
3 可以直接获取数据库连接信息账号密码,以及后台地址等更多敏感信息。
4 可以用来下载该网站源码,做代码审计,发现更大的漏洞造成更大的危害
5 网站存在包含SVN信息的文件,这是网站源码的版本控制器私有文件,里面包含SVN服务的地址、提交的私有文件名、SVN用户名等信息,该信息有助于攻击者更全面了解网站的架构,为攻击者入侵网站提供帮助。
6 该信息泄露会暴露服务器的敏感信息,使攻击者能够通过泄露的信息进行进一步入侵。
Repair:查找服务器上所有.svn隐藏文件夹,删除
以下命令删除当前目录下.svn文件夹
find . -type d -name ".svn"|xargs rm -rf
rm -rf `find . -type d -name .svn`
find . -name ".svn" -type d | xargs rm -fr
find . -name ".svn" -type d | xargs -n1 rm -R
}
git 模板
{
Url:http://www.langzi.fun/.git,
Description:敏感信息泄露,
Cause:这里当网站维护(开发)人员在从托管网站pull代码的时候 , 也会将这个储存了所有的版本信息的.git文件夹下载到服务器的Web目录下 , 这样的话 , 攻击者就可以利用这个目录 , 去下载git文件夹 , 就可以利用其中储存的版本控制信息 , 完全恢复网站后台的代码和目录结构 , 当然 , 一般网站都会涉及到数据库操作 , 而一般来说 , 需要链接数据库就需要用户名/密码/端口/库名等信息 , 而这些信息肯定会在网站后台的源码里面又体现 , 因此这种情况是极其危险的 , 还有 , 一旦服务器开放了数据库的远程连接功能 , 攻击者就可以利用从源码中找到的数据库用户名和密码对远程数据库进行登陆 , 危险性不言而喻
Risk:
1 下载代码开发时候的全部源代码,敏感文件泄露是高危漏洞之一,敏感文件包括数据库配置信息,网站后台路径,物理路径泄露等,此漏洞可以帮助攻击者进一步攻击,敞开系统的大门。
2 可以列出网站目录,进而发现管理登录的网址
3 可以直接获取数据库连接信息账号密码,以及后台地址等更多敏感信息。
4 可以用来下载该网站源码,做代码审计,发现更大的漏洞造成更大的危害
5 该信息泄露会暴露服务器的敏感信息,使攻击者能够通过泄露的信息进行进一步入侵。
6 所有commiter的邮箱帐号信息,包括(可能)内部的帐号和密码
Repair:删掉.git目录或者重命名此目录。
}
备份源码泄露 模板
{
Url:http://www.langzi.fun/langzi.rar:360M,
Description:敏感信息泄露,
Cause:
1 网站自动备份,备份文件名和路径容易被猜解。
2 管理员手动备份文件名,用的域名作为备份文件名称,并且放置在根目录。
Risk:
1网站存在备份文件:网站存在备份文件,例如数据库备份文件、网站源码备份文件等,攻击者利用该信息可以更容易得到网站权限,导致网站被黑。
2敏感文件泄露是高危漏洞之一,敏感文件包括数据库配置信息,网站后台路径,物理路径泄露等,此漏洞可以帮助攻击者进一步攻击,敞开系统的大门。
3 由于目标备份文件较大(xxx.G),可能存在更多敏感数据泄露
4 该备份文件被下载后,可以被用来做代码审计,进而造成更大的危害
5 该信息泄露会暴露服务器的敏感信息,使攻击者能够通过泄露的信息进行进一步入侵。
6 当然 , 一般网站都会涉及到数据库操作 , 而一般来说 , 需要链接数据库就需要用户名/密码/端口/库名等信息 , 而这些信息肯定会在网站后台的源码里面又体现 , 因此这种情况是极其危险的 , 还有 , 一旦服务器开放了数据库的远程连接功能 , 攻击者就可以利用从源码中找到的数据库用户名和密码对远程数据库进行登陆 , 危险性不言而喻
Repair:删掉备份文件或者重命名备份文件名。
}
在结构设计上,本来三个扫描验证的功能都集成在一个函数中,用列表存储数据,但是发现这样不利于传递数据到模板生成漏洞报告页面,因为扫描备份文件的时候可能存在多个文件,于是按照功能独立出来。但是其他的网站或者数据库未授权倒是可以改动一下的。
svn和git源码泄露分别返回如下的结构数据
http://www.langzi.fun/.git/config:GIT源码泄露
http://www.langzi.fun//.svn/entries:SVN源码泄露
但是备份文件返回的对象是一个列表,返回的格式如下:
[http://www.langzi.fun/a.zip:500M,http://www.langzi.fun/lang.zip:600M]
上面的如果没有返回扫描到的结果就返回None
调用方法:
'''
三个函数,返回的结果分别是 1 SVN字符串 2 GIT字符串 3 BACK列表
分别是
scan_backup() 列表
scan_git() 字符串
scan_svn() 字符串
如果没有结果就返回None
'''
SQL注入漏洞 模板
采用的Lang_SQL_Injection_3.3版本移植功能,支持其全部功能和作用,关于设置扫描等级可以再config.ini中设置。
调用方法
'''
检测sql注入,传入两个参数,网址和扫描等级
如果存在注入,就返回字典
res = scan_sql('http://xy.5971.com',level=1)
if res != None:
print res['title']
print res['url']
print res['common']
print res['report_0']
# 注入方式,参数等等
print res['report_1']
# 数据库信息等
'''
XSS漏洞 模板
采用Lang_XSS_scan_1.1版本移植全部功能,同样支持其全部功能和作用,设置扫描等级同样可以可以再config.ini中设置。
模板需要传入参数:漏洞网址
扫描验证返回的结果:一个字典,有4个键值
在原版中自动生成的结果本来是这样的
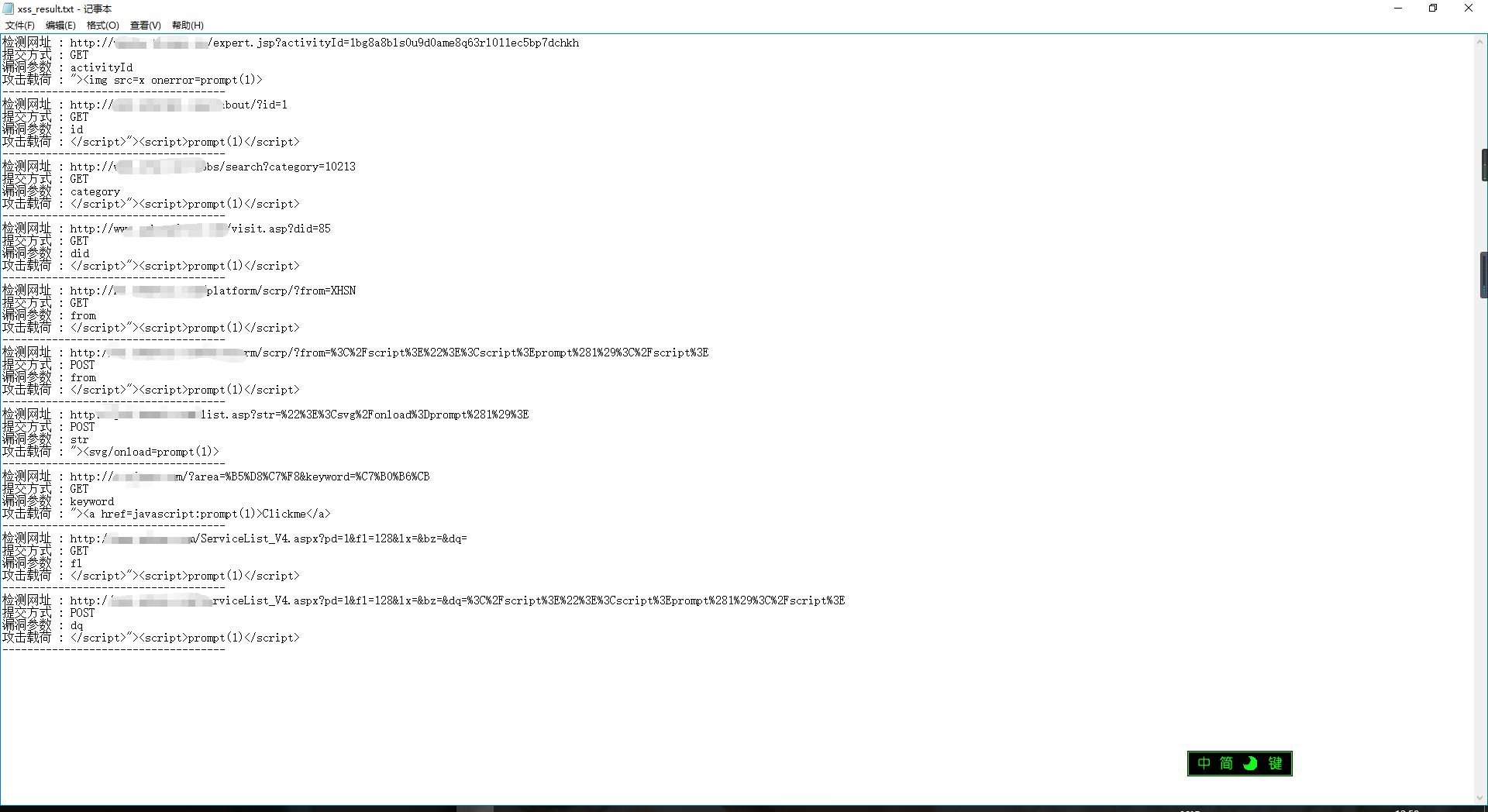
返回结果
检测网址 : http://xxxxxx.com/?area=%B5%D8%C7%F8&keyword=%C7%B0%B6%CB
提交方式 : GET
漏洞参数 : keyword
攻击载荷 : "><a href=javascript:prompt(1)>Clickme</a>
按照前文所需求设置,应该是如下格式的内容写入:
{
url:http://xxxxxx.com/?area=%B5%D8%C7%F8&keyword=%C7%B0%B6%CB
description:反射型XSS漏洞
cause:网站本身设计不严谨,导致执行用户提交的恶意js脚本,对网站自身造成危害。xss漏洞是web渗透测试中最常见而又使用最灵活的一个漏洞。它允许恶意用户将代码注入到网页上,其他用户在观看网页时就会受到影响。
risk:
1 cookie劫持(窃取cookie, 因为cookie能够代表用户的身份,所以盗取了cookie之后,就可以伪造用户去做一些事情了,这个产生的危害是非常可怕的。)
2 钓鱼,利用xss构造出一个登录框,骗取用户账户密码。
3 Xss蠕虫(利用xss漏洞进行传播)
4 修改网页代码
5 利用网站重定向
repair:
1 用户名、邮箱等表单验证(前台/服务器二次验证)
2 富文本使用白名单机制等
3 设置 cookie 时加入 HttpOnly 可使 js 脚本无法获取 cookie
4 定义允许的资源加载地址,比如图片 / 视频 / JS 脚本等
5 HTTPS加密访问
}
根据模板的内容和结构,唯一需要传入的就是漏洞的网址,然后把返回的结果并行写入报告。
调用的方法:
'''
扫描xss
res = scan_xss('http://www.xxxxxxxx.com')
if res != None:
print res['url']
print res['request']
print res['payload']
返回结果:{'url': 'http://www.xxxxx.com/service.asp?id=4', 'request': 'GET', 'payload': '</script>"><script>prompt(1)</script>', 'value': 'id'}
'''
数据库弱口令 模板
这个漏洞的危害不容置疑,相对来说需要写的报告要更加精简到位。
模板需要传入参数:原始网址
扫描验证返回的结果:字典,有5个键值
{
url:http://www.baidu.com
description:数据库弱口令
cause:网站管理员使用默认账号密码并且设置相对简单的密码导致
risk:
1 整个数据库的信息泄露
2 数据库用户权限大,可以直接写入木马控制服务器
3 可导致数据库被人下载并出售,造成巨大损失
4 造成用户信息泄露,可以被黑客用来尝试破解用户其他平台的密码
5 对整个网站和公司企业造成巨大的损失
repair:
1 设置复杂的密码,比如Lan92i@f9ZhoA@#¥
2 禁止最高权限账号外部访问,只能本地访问
3 对每个用户做权限设置,只能查询权限下的表的内容数据
}
数据库弱口令的前提是要获取到网站对应的IP地址,然后尝试弱口令漏洞验证报告,所以对模板传入的是网址,继续添加的内容如下:
{
url:http://www.langzi.fun
IP:127.0.0.1
database:mysql
username:root
password:root
}
返回的结果字典有5个键值,然后写入即可
未授权访问系列 模板
因为有IP未授权访问漏洞和URL未授权访问漏洞扫描验证的漏洞比较多,如果每个都要弄专门的一套模板得麻烦死,所以在扫描器内部返回的数据信息模板渲染,本来返回的只是一条漏洞网址,修改成一个字典,内部的值可以直渲染到模板
管理后台弱口令
因为相关的代码还没有写完,关于验证码需要使用到卷积神经网络并且要进行模型训练,所以后期要闭关一段时间稍微学一下机器学习的知识。
URL跳转漏洞
过渡时期
Auto_ExtrAct系列
花了三天时间基于其他作品的源码上,实现了安全巡航过度的测试软件,命名为AutoExtrAct系列,实现挂机,全自动扫描漏洞并自动化生成报表(暂时有源码泄露,sql注入,xss)
涉及知识点:异步多进程协程,广度优先原则,python自动化生成word,拉起sqlmap检测注入,selenium复现漏洞,pillow截图,mysql管理,aiomysql异步数据库操作,全程自动化
挂机一天的结果

确认安全巡航将会采用数据库管理,结合flask实现后端,前端用bootstrap+vue,核心是全程自动化扫洞后生成报表,将会借取yolanda的核心,实现无限采集功能,将会设置关键词爬行等等,不过一切等以后再说吧…..
开放XSS社区版下载,解压密码为域名
适合放在虚拟机里头挂着刷
DOWNLOAD URL 一次性导入不超过50个url噢~
19年度礼物
概述
实现全自动漏洞扫描自动复现生成报告,全程自动化
又到了一年一度的520年度环节,去年为基佬们准备的礼物是YolandaScan,新年礼物是安全巡航0.95模型机,虽然在现在看来都很弱,不够完善,不过也是当初的美好回忆。
今年帅气的群主为大家准备的年度礼物是基于安全巡航过度版本的extract1.5版本,虽然功能少,也不够智能化,但是是一个美好的开始~
虽然工具挺破,还消耗资源,又不成熟….但是也是一点点小心意….
运行条件
- 安装 Microsoft Office
- 安装Firefox浏览器
- 安装vc++2015相关库
- 安装python2,并添加到系统环境变量//即cmd下输入python进入python2交互界面
- 安装Mysql数据库
- 运行目录不要存在中文
环境准备
- 将目录下的创建数据库文件导入,创建数据库
- 配置文件
参数介绍
[Server]
host = 127.0.0.1
# 数据库地址
username = root
password = root
db = langzi_scan
# 数据库名
port = 3306
# 端口
[Config]
thread_s = 16
# 扫描线程数,一般不能设置太大
check_env = 1
# 是否每次运行前检测运行环境
start_on = 0
# 是否从数据库中获取数据继续扫描
check_env参数:每次运行前检测相关运行环境是否正确配置,设置成1则会每次启动扫描器前自动检测运行环境
start_on参数:设置成1再数据库存在数据的情况下,不导入新的网址,直接从数据库提取网址进行扫描,设置成0则每次启动主程序都会提示导入网址到数据库,燃后开始扫描。
使用方法
批量采集url保存在文本
启动主程序
导入采集好的url即可
全部自动生成报表使用浏览器截图,无需操作
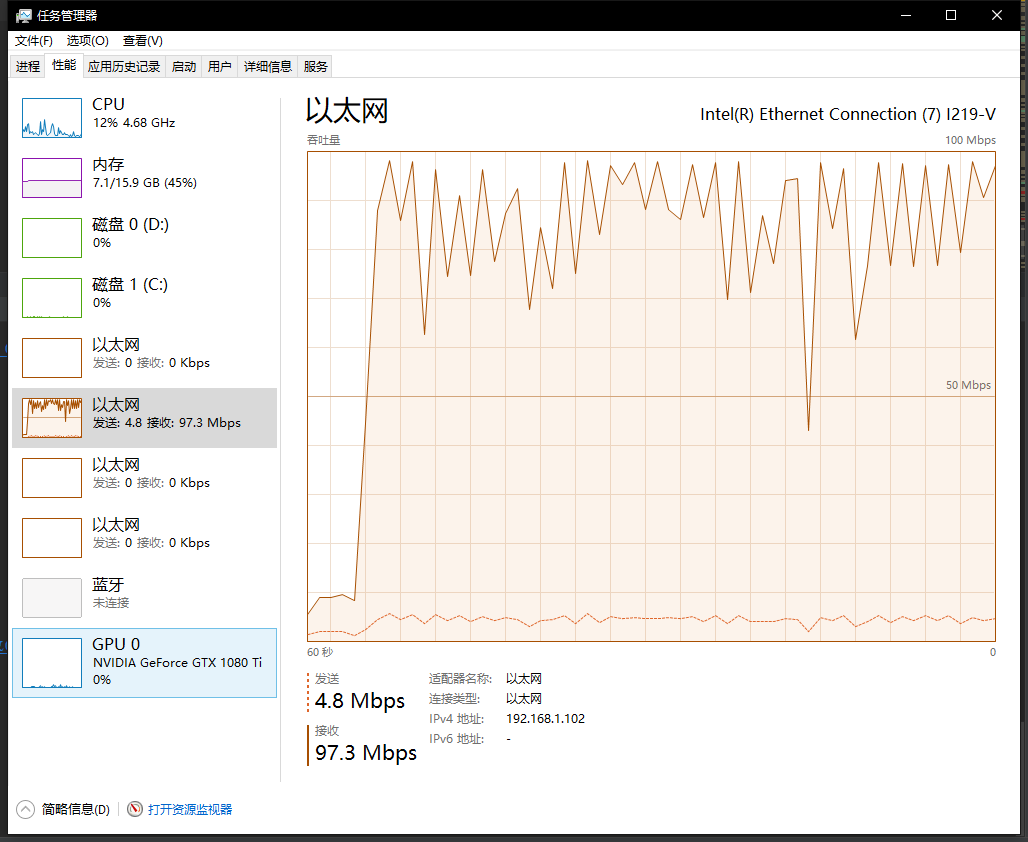
资源消耗
对主机配置略高,最好是SSD硬盘[启动Firefox]
使用的线程数基于CPU处理核心数
个人使用16个线程,在全部启动并发情况下资源消耗

补充
目前稳定支持sql注入,xss,源码泄露,url跳转四种类型漏洞扫描,关于其他的未授权访问,数据库弱口令,以及各种未授权漏洞,代码执行,命令执行,信息泄露等等将会在以后慢慢更新
目录下生成文本内容包括任意url跳转,xss,源码泄露相关信息,然后通过Firefox浏览器直接渲染检测是否出现弹窗,出现弹窗直接捕获截图保存
建议是挂在虚拟机跑,不影响物理机工作,自动生成扫描结果
随后你就可以去做一些你爱做的事
关键点:
不支持扫描国内GOV 与 EDU
每次最大扫描数量设置为500
不管你导入的网址多大,只会从中提取500个网址加载到数据库扫描
配置文件CONFIG.INI的编码为ANSI
可以删除的文件
目录下的所有图片
result文件夹
image文件夹
*result.txt
*log.txt
捡漏
虽然不能让你称霸SRC,但是在补天能换几桶泡面还是可以的
存在大概20%的误报吧,每次提交前需要手动复现的噢
AuTo_ExtrAct 2.0系统构架设计
AuTo_ExtrAct作为安全巡航的前身作品,并不会使用数据库存储数据,仅仅用数据库做任务调度派发。
so,一些其他的敏感信息也不用考虑保存到数据库。
关于安全巡航将会在AuTo_ExtrAct完全成熟后,使用Django实现后端数据展示,使用数据库存储数据,不再需要自动生成扫描结果,改成在后台管理界面,点击相关信息找到漏洞,点击生成,即可生成漏洞报表,到时候对报表在多做优化吧。
关于是否要要CMS检测和网页的相关信息,比如服务器类型加入,想了许久还是不添加这个功能,不然会显得臃肿。
功能模块化
MainConsole
- 主控制台,不执行扫描任务
- 主要负责运行环境检测
- 任务调度
- 目录文件检测
- 数据库初始化
- 数据url导入等
- 支持导入前url存活检测
ExtrUrs
- 负责对数据库中URL提取超链接和静态网页链接,然后保存入库
- 接口处使用线程池启动
- 使用队列锁控制数据提取
- 需要数据:主模块MainConsole导入的主URL
ExtrUrr
- 负责对数据库中URL提取带.action/.do/.jsp/php反序列化/接口处执行命令/带有可能ssrf的参数网址/等等存在命令执行的网址链接,然后保存入库
- 常见存在命令执行的有tp3,struct,weblogic,joomla,jboss等
- 接口处使用线程池启动
- 使用队列锁控制数据提取
- 需要数据:主模块MainConsole导入的主URL
ExtrSql
- 负责SQL注入检测,并生成自动报表(word格式)
- 接口处使用异步多进程启动
- 使用队列锁控制数据提取
- 搭载SQLMAP1.3.5版本,之前搭载1.2.11版本会存在误报情况
- 需要继续定制重写部分SQLMAP运行逻辑代码,方便所有扫描结果保存
- 需要的数据为:ExtrUrl模块获取到的动态超链接与静态链接
ExtrXss
- 负责XSS检测,并生成自动报表(word格式,自动化截图)
- 需要支持设置扫描等级
- 接口处使用异步多进程启动
- 使用队列锁控制数据提取
- 需要的数据为:ExtrUrl模块获取到的动态超链接
ExtrUrl
- 负责url跳转漏洞检测,并生成自动报表(word格式,取消截图功能)
- 接口处使用异步多进程启动
- 使用队列锁控制数据提取
- 需要的数据为:ExtrUrl模块获取到的动态超链接
ExtrBac
- 负责源码泄露检测,并生成自动报表(word格式,取消截图功能,新增git泄露与svn泄露)【与backup.txt配合使用】
- 需要支持设置扫描等级
- 接口处使用异步多进程启动
- 使用队列锁控制数据提取
- 取消使用两个模块实现源码泄露扫描与生成报表,合并在一起
- 继续使用多进程异步协程框架,继续使用基于广度优先原则,修改策略为:从数据库一次性提取多个网址扫描
- 需要数据:主模块MainConsole导入的主URL
ExtrRce
- 负责命令执行&代码执行,并生成自动报表(word格式,需要截图)
- 接口处使用异步多进程启动
- 使用队列锁控制数据提取
- 需要的数据为:ExtrUrr模块获取到的动态超链接,按照类型进行检测
ExtrLfi
- 负责文件包含漏洞检测,并生成自动报表(word格式,需要截图)
- 接口处使用异步多进程启动
- 使用队列锁控制数据提取
- 需要的数据为:ExtrUrl模块获取到的动态超链接
ExtrSsf
- 负责ssrf漏洞检测,并生成自动报表(word格式,需要截图)
- 检测方式可以基于http协议与file协议,字典使用默认放在内存吧
- 别忘了进行url编码
- 接口处使用异步多进程启动
- 使用队列锁控制数据提取
- 需要的数据为:ExtrUrl模块获取到的动态超链接
ExtrAut
- 负责常见的未授权访问漏洞检测,并生成自动报表(word格式,需要截图)
- 接口处使用异步多进程启动
- 使用队列锁控制数据提取
- 需要数据:主模块MainConsole导入的主URL
ExtrInf
- 负责敏感信息扫描(需要有配置文件),url提供的开放端口扫描,并自动生成报表(html格式,需要有常见的敏感数据保存,无需截图)
- 接口处使用异步多进程启动
- 使用队列锁控制数据提取
- 需要数据:主模块MainConsole导入的主URL
ExtrJsp (暂时不用)
- 负责JSONP劫持扫描检测
- 接口处使用异步多进程启动
- 使用队列锁控制数据提取
- 需要数据:需要使用mitmproxy进行代码捕获url链接,常规的爬行是无法获取到敏感数据
ExtrCor
- 负责CORS劫持扫描检测
- 接口处使用异步多进程启动
- 使用队列锁控制数据提取
- 需要数据:主模块MainConsole导入的主URL
ExtrSub
- 负责定时监控网址子域名,不间断的使用子域名爆破+网页中爬取URL,如果匹配到相关域名,则保存到主数据库【与Subdomain.txt配合使用】
- 递归监控子域名爆破
- 接口处使用异步多进程启动
- 使用队列锁控制数据提取
- 需要数据:主模块MainConsole导入的主URL
backup.txt
- 存储扫描备份文件字典
Subdomain.txt
- 存储监控的域名,保存的格式如下;
baidu.com
jd.com
qq.com
...
如果内容为
*
那么会停止子域名爆破功能,在网页提取url的时候,把提取到的url不经过任何过滤,直接保存到主数据库。(默认会过滤gov&edu)
但是不建议这么做,因为这样会导致变成无限制的无限扫描,永远停不下来的那种。
Subdomaindic.txt
- 子域名爆破字典
Config.ini
- 重要的配置文件
- 配置数据库登陆信息
- 配置扫描进程数量
- 配置xss,备份文件扫描等级
- 配置是否开启扫描功能(比如关闭SQL注入扫描功能,是否需要不间断的监控子域名)
- 配置是否定时重启任务(可以自定义重启扫描器时间)
- 配置是否从数据库加载数据继续扫描(当重启电脑后,数据库还有数据没有扫描完毕,可以通过这里设置继续扫描)
default.docx
- 生成报表的重要模板文件
需要在github上多找找命令执行和返回的信息,需要多验证一些敏感信息泄露的路径
数据库设计
既然只是过度实验品,那么功能自然是越精简月号,这样方便后期功能移植,so,数据库必须要做的极度的精简,但是考虑到有大量的并发,还是分三张表减少服务器压力比较好。
主索引数据库
sec_index
- url(网址:主键)
- unauth (获取未授权需要的url,状态:0/1)
- extrurs(爬行获取静态链接和动态参数,状态:0/1)
- extrurr(爬行获取命令执行需要的url,状态:0/1)
- subdomain(获取子域名,既需要爬行页面相关内容,状态:0/1)
- backup(扫描源码泄露,状态:0/1)
- info(扫描敏感信息路径泄露与开放端口服务,状态:0/1)
- cors(扫描sors劫持,状态:0/1)
静态链接与动态超链接数据库
sec_links_0 静态网页
- url(网址:主键)
- links(一个列表,其中保存静态网页链接)
- sql(扫描SQL注入,状态:0/1)
sec_links_1 动态链接【按照url深度分类,每层一个】
- url(网址:主键)
- links(一个列表,其中保存动态超链接)
- sql(扫描SQL注入,状态:0/1)
- xss(扫描xss,状态:0/1)
- url(扫描url跳转,状态:0/1)
- lfi(扫描文件包含,文件读取,状态:0/1)
- rce(扫描命令执行,状态:0/1)
sec_links_2 动态链接【按照url参数路径去重复,不限制个数,但是超过50个就随机抽取50个】
- url(网址:主键)
- links(一个列表,其中保存动态超链接)
- sql(扫描SQL注入,状态:0/1)
- xss(扫描xss,状态:0/1)
- url(扫描url跳转,状态:0/1)
- lfi(扫描文件包含,文件读取,状态:0/1)
- rce(扫描命令执行,状态:0/1)
这一点可以在配置文件中的URL选择等级,
比如设置level = 1 那么 扫描links0和links1两张表(sql注入要多扫描一张)
设置2 则扫描links0和links2,设置成3则扫描这整整四张表所有的sql链接。
动态超链接数据库
sec_rlinks
- url(网址:主键)
- links(一个字典,其中保存按照命令执行漏洞类型的url链接,比如action,do,jsp,php等)
- rce(命令执行扫描状态,状态:0/1)
- ssf(扫描ssrf,状态:0/1)
提起一下,数据库的表名字不能是sql
配置文件启动信息
配置文件是和数据库同等重要的文件,好的数据库设计关系到整个系统的构架,好的配置文件关系到整个软件的运行逻辑。
初略设计如下,肯定会修改:
[Server]
然而理想与现实还是有很大的差距,很多功能模块因为构架不一致,必须要单独分成模块。总的来说,首先设计好构架,包括数据库结构,功能结构,配置项结构做好设计后,开始写代码才能有思路和头绪。
补充:
- 需要加一张表,这张表保存获取url超链接失败的url
睡了一觉醒来发现,其实很多地方还有待重构….上面的构架部分还需要重写….
LANGZI_SRC_安全巡航 0.97版本
LANGZI_SRC_安全巡航 是一款集成漏扫,验证,资产监控,自动复现并且生成结果表报的工具,实现初衷是为了帮助白帽子在SRC中节约时间成本的自动化工具。
阅读完此文并配置环境大约需要20分钟,为了避免非零基础人群感到身体不适、头晕恶心、易怒及粗口,请不要查看以下内容。
本软件只做初步探测,无攻击性行为。请使用者遵守《中华人民共和国网络安全法》,勿用于非授权的测试,检测目标仅限于各大SRC,补天SRC,公益SRC进行测试。
最后更新时间:2019-6-26 22:24
运行环境
- 安装 Microsoft Office
- 安装Firefox浏览器
- 安装vc++2015相关库
- 安装python2,并添加到系统环境变量//即cmd下输入python进入python2交互界面
- 安装Mysql数据库
- 运行目录不要存在中文
配置环境
- 指向目录下的 数据库安装文件.sql,安装数据库
- 配置Config.ini配置文件
- 准备好采集的SRC_URL文本,使用URL采集软件采集一批网址,然后保存在一个新的文本文件(此步骤可不做)
资源消耗
对主机配置略高,最好是SSD硬盘[启动Firefox]
使用的线程数基于CPU处理核心数
实验使用16个线程,在全部启动并发情况下资源消耗
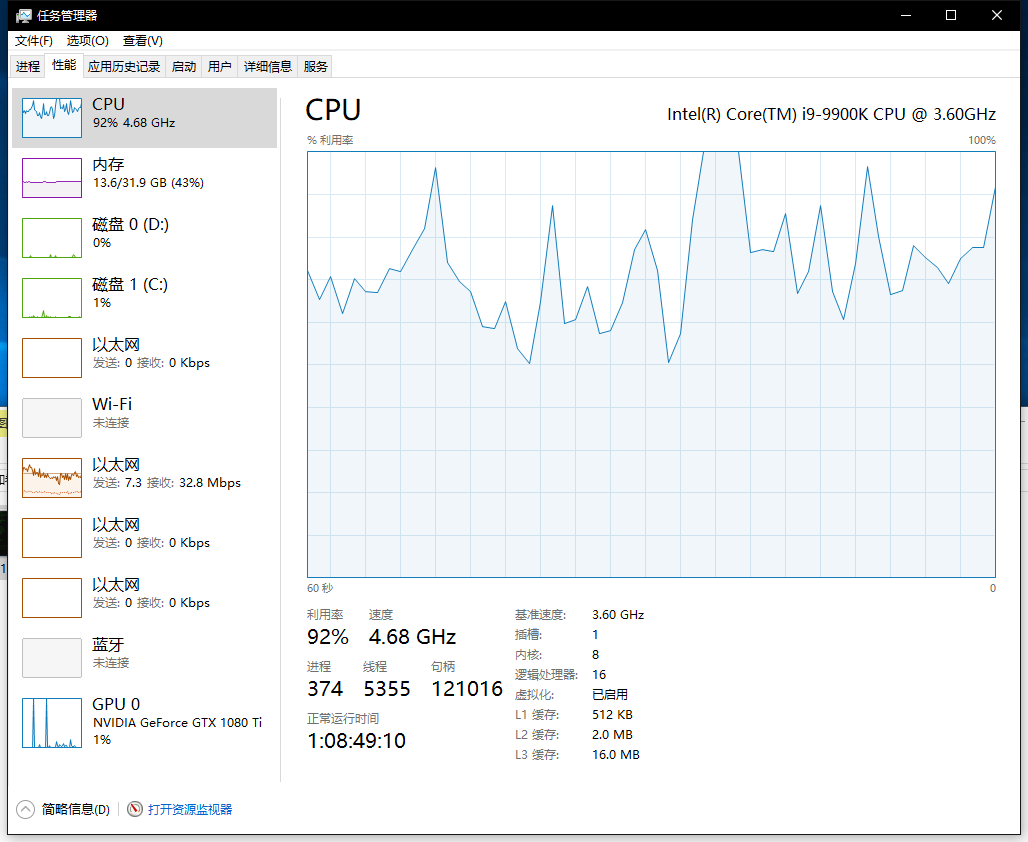
可以看到还是比较吃资源,所以尽量不要直接开启全部扫描模块,可以先开启部分模块做资产收集,然后开始检测。
即花一天的时间跑子域名监控功能和超链接爬行功能,等到数据库资产差不多了就关闭资产监控功能,开启漏扫功能。
进程销毁
当退出关闭扫描器后,其下活动进程会在3分钟内自行关闭,可以通过任务管理器查看进程是否销毁。
主扫描表
再开启子域名监控的条件下,通过爆破,搜索引擎获取,以及网页爬行。三种方式不间断的获取domains.txt其下受监控的子域名,保存在主扫描表
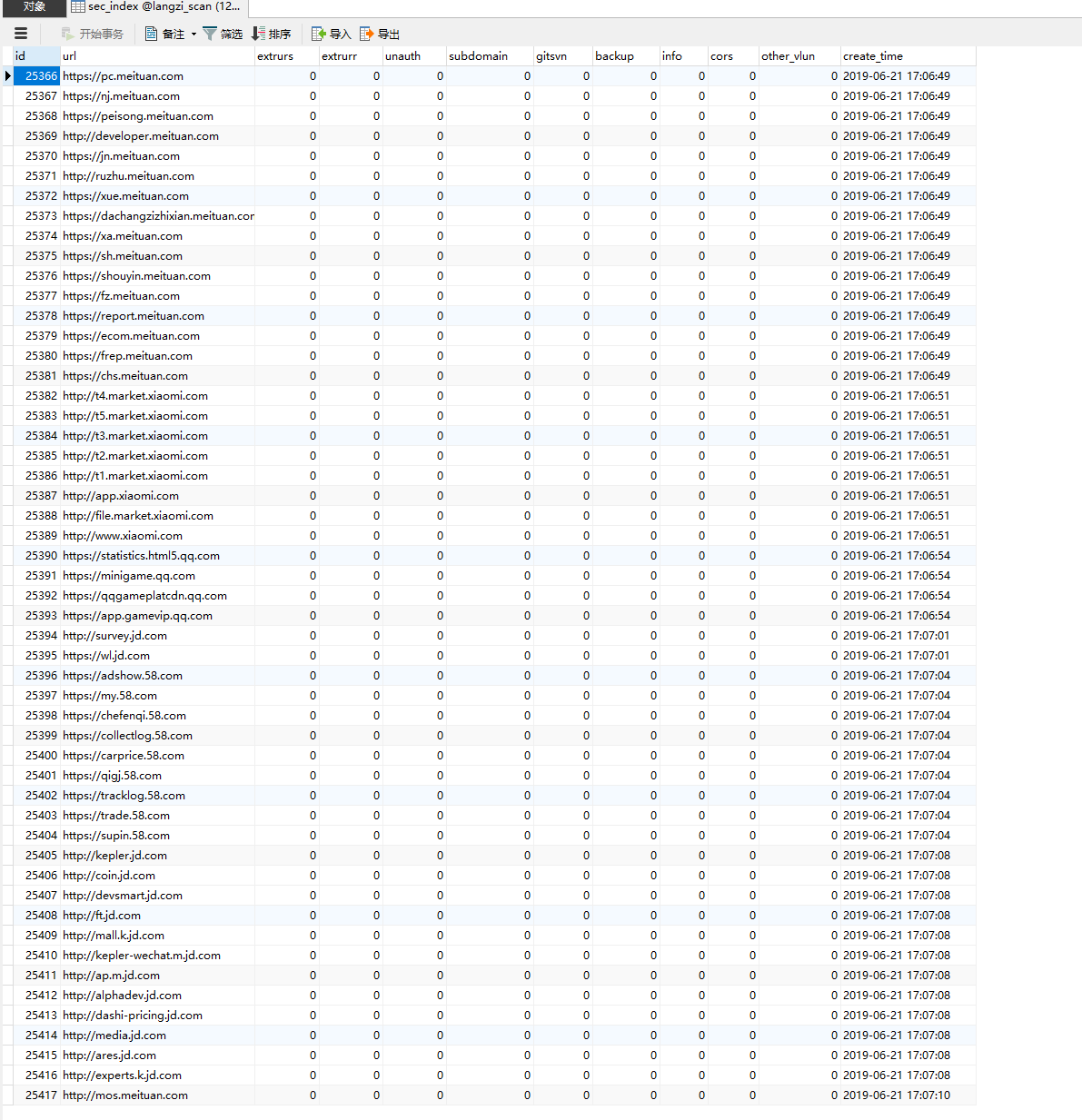
sec_index主表保存大量受监控的子域名
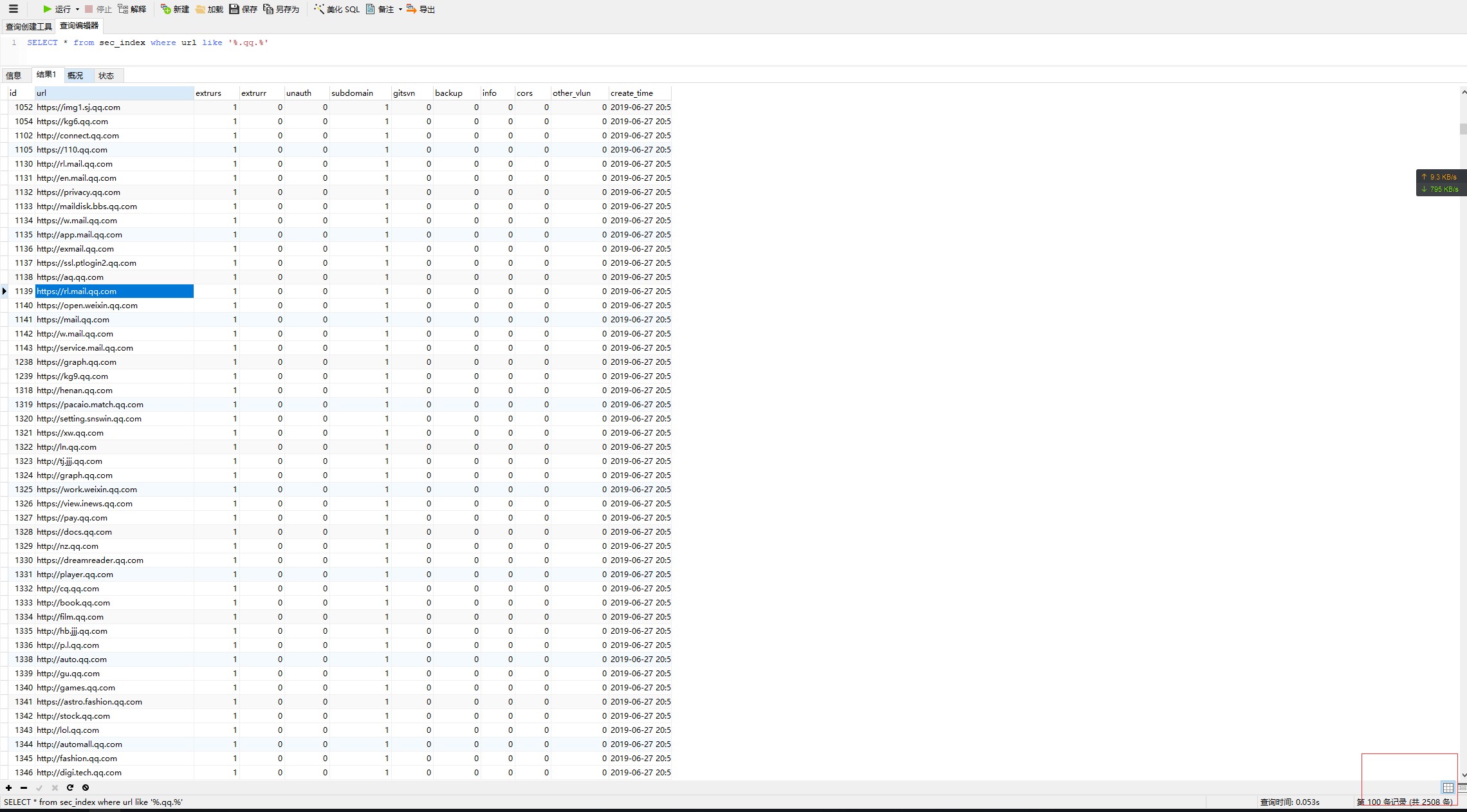
SELECT * from sec_index where url like '%.qq.%'
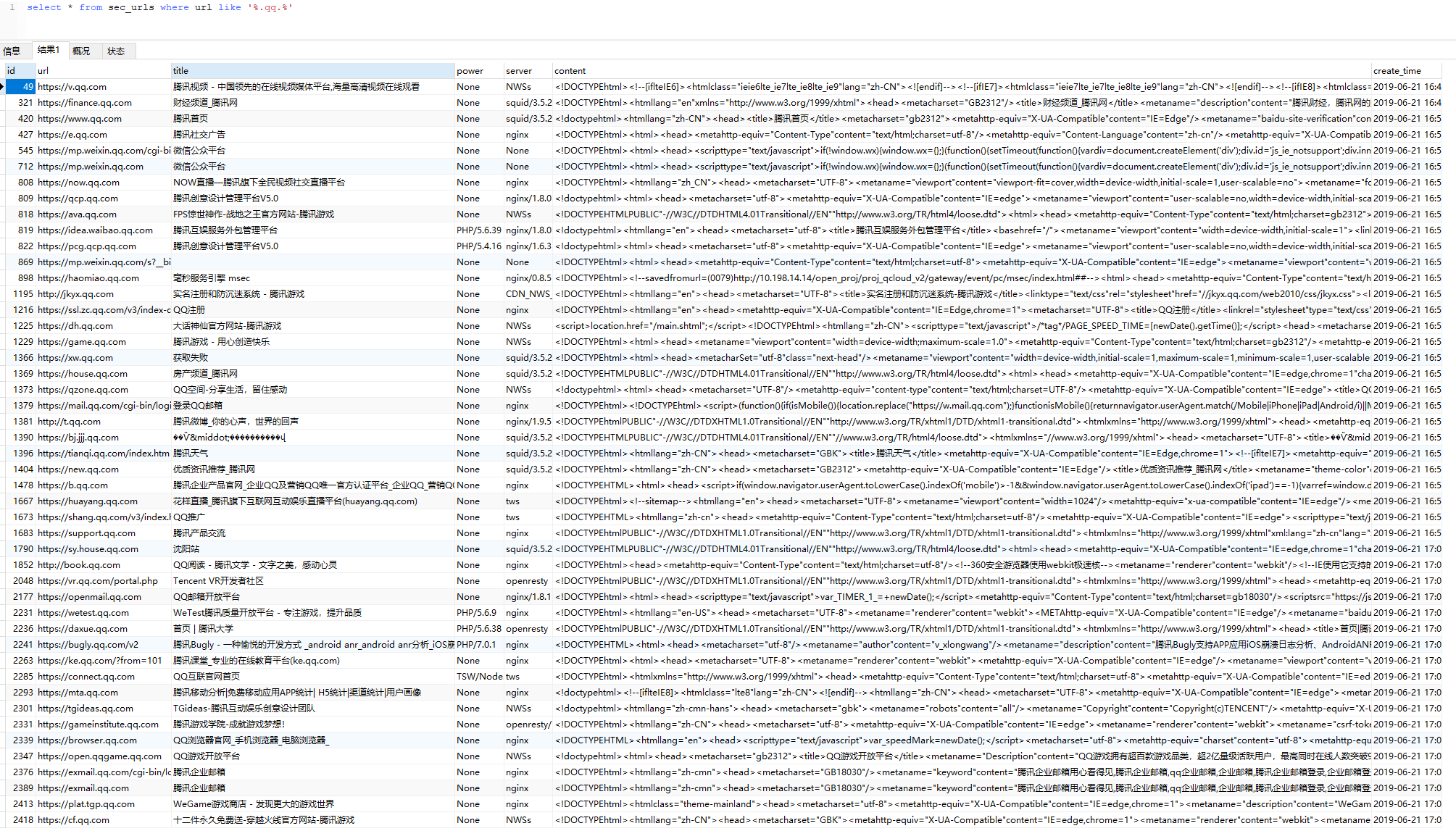
持续性WEB资产获取
在保存网址表中,保存着通过爬行获取到所有的友链数据,包括网址,标题,使用语言,服务器类型,网页内容。

等到数据量庞大起来后,可以做批量的数据采集调用,比如
select * from sec_urls where title like '%腾讯%',
select * from sec_urls where url like '%.qq.%',
select * from sec_urls where content like '%后台管理系统%',
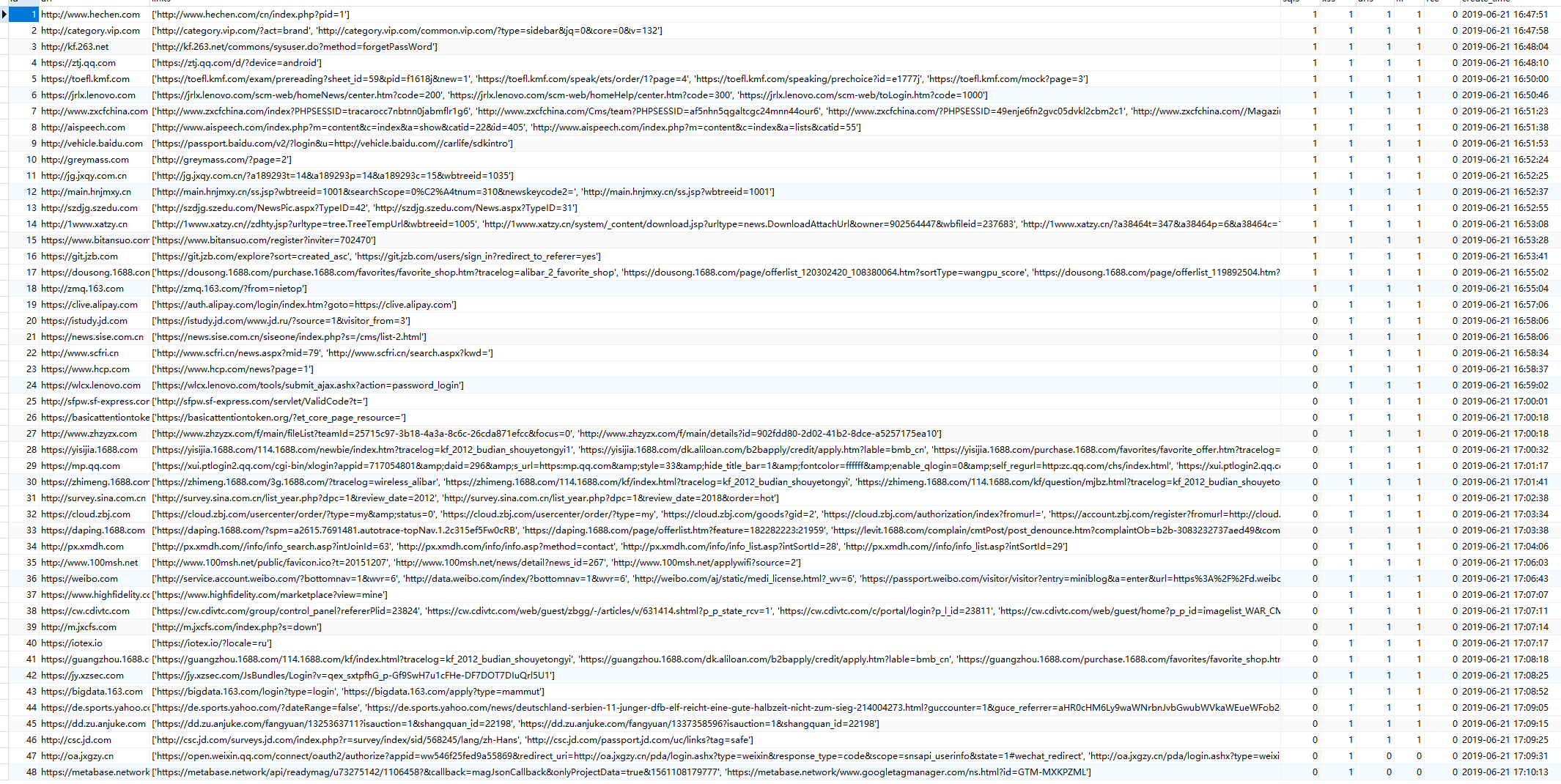
超链接获取
在超链接表保存着网址的超链接和静态链接,其中静态链接可以使用sqlmap尝试伪静态注入,其他的可以尝试进行不同漏洞检测
报表自动化
在漏扫中填写报告也是个体力活,于是尝试实现了自动化实现,虽然被人骂懒死,但是确实挺方便的。



配置文件
目录下的Config.ini是核心启动控制台,预读大约需要5分钟。
注意,Config.ini 文件编码为 ANSI,如果不一致则会报错
[Server]
# 数据库配置项
# 可以做分布式
host = 127.0.0.1
username = root
password = root
db = langzi_scan
port = 3306
[Common_Config]
threads = 16
# 线程数
# 建议4-32之间
check_env = 1
# 每次启动前是否检测运行环境是否完整
# 可选 0/关闭 1/开启
key = l95-la4-zh3-li0
[Start_Console]
start_on = 0
# 选择批量扫描的URL文本,如果数据库有数据的话,也可以选择不导入文本,直接从数据库继续扫描
# 可以理解为,把你采集好的网址导入然后进行扫描
# 可选 1/不提示导入URL文本,直接从数据库提取数据
# 可选 0/提示导入URL文本
check_alive = 0
# 检测导入文本的URL存活性检测,只有在设置START_ON=1情况下有效
# 可选 0/关闭 1/开启
[Scan_Modules]
ExtrUrs = 1
# 提取URL的超链接
# 可选 0/关闭 1/开启
ExtrUrr = 1
# 提取URL的超链接,不过有些臃肿,暂时移除
# 可选 0/关闭 1/开启
ExtrSql = 1
# 扫描SQL注入漏洞
# 可选 0/关闭 1/开启
ExtrXss = 1
# 扫描XSS漏洞
# 可选 0/关闭 1/开启
ExtrUrl = 1
# 扫描URL跳转漏洞
# 可选 0/关闭 1/开启
ExtrBac = 1
# 扫描备份文件源码泄露漏洞
# 可选 0/关闭 1/开启
ExtrRce = 1
# 扫描命令执行漏洞,不过效率太低,目前版本移除该功能
# 可选 0/关闭 1/开启
ExtrLfi = 1
# 扫描任意文件读取漏洞
# 可选 0/关闭 1/开启
ExtrSsf = 1
# 扫描SSRF漏洞,效率和误报不算理想,目前版本移除该功能
# 可选 0/关闭 1/开启
ExtrAut = 1
# 扫描未授权访问漏洞
# 可选 0/关闭 1/开启
ExtrInf = 1
# 扫描信息泄露,包括url开发的敏感端口,敏感路径,后台登陆,搜索引擎寻找漏洞
# 生成HTML信息报表,和漏扫的结果不一致,显得臃肿,目前版本移除该功能
# 可选 0/关闭 1/开启
ExtrGis = 1
# git svn 源码泄露扫描
# 可选 0/关闭 1/开启
ExtrCor = 1
# 扫描CORS劫持漏洞,一些大厂比较多,但是危害性比较小,所以一般都不扫描,设置为0
# 可选 0/关闭 1/开启
ExtrSub_Brute = 1
# 子域名监控功能 之 子域名爆破
# 可选 0/关闭 1/开启
ExtrSub_Baidu = 1
# 子域名监控功能 之 搜索引擎获取子域名
# 可选 0/关闭 1/开启
ExtrSub_Web = 1
# 子域名监控功能 之 通过网址爬行获取子域名
# 该模块还负责爬行友链信息保存到sec_urls表的功能,so,如果你不想爬采集太多的网址,请关闭这个
# 在 Keep_Scan = 1 的情况下,还负责把所有的友链保存到漏扫任务表中
# 可选 0/关闭 1/开启
Keep_Scan = 0
# 获取网址中所有的友链,并且把获取到的友链保存到扫描表,基本上可以实现见谁日谁,实现无限挂机扫描
# 原理就是把一个网址的友链全部保存到漏扫任务表,基本上越爬越多
# 扫描机制来源于Yolanda_Scan,但是这一点也是被人诟病的一点,不建议开启
# 必须在 ExtrSub_Web = 1 的情况下才有效
# 可选 0/关闭 1/开启
[Scan_Levels]
Scan_Level = 1
# 扫描等级
# 可选 1/低级 2/中级 3/高级
# 默认开1就够了,当然也可选择2或者3
Xss_Level = 1
# XSS扫描等级
# 可选 1/低级 2/中级 3/高级 4/特级
# 默认开1就够了
Back_Level = 1
# 备份文件扫描等级
# 可选 1/低级 2/中级 3/高级
# 不同等级对应的扫描字典规则都不一样,越高代表字典数量越多
# 默认开1就够了
数据库详情
明确每张表的功能和包含数据,方便做调试与资产监控,以及自定义的重复性扫描验证。
功能详见注释
create database if not exists Langzi_Scan;
use Langzi_Scan;
create table if not exists Sec_Index(
id int primary key auto_increment,
url varchar(80),
extrurs int(1) default 0 comment '爬行获取静态链接和动态参数,状态:0/1',
extrurr int(1) default 0 comment '爬行获取命令执行需要的url,状态:0/1',
unauth int(1) default 0 comment '(获取未授权需要的url,状态:0/1)',
subdomain int(1) default 0 comment '获取子域名,既需要爬行页面相关内容,状态:0/1)',
gitsvn int(1) default 0 comment '扫描gitsvn源码泄露,状态:0/1)',
backup int(1) default 0 comment '扫描源码泄露,状态:0/1)',
info int(1) default 0 comment '(扫描敏感信息路径泄露与开放端口服务,状态:0/1)',
cors int(1) default 0 comment '(扫描sors劫持,状态:0/1)',
other_vlun int(1) default 0 comment '获取其他类型漏洞,状态:0/1)',
create_time timestamp DEFAULT CURRENT_TIMESTAMP
)charset =utf8mb4;
alter table Sec_Index add unique(url);
create table if not exists Sec_Links_0(
id int primary key auto_increment,
url varchar(100),
links longtext comment '静态链接,类型是一个列表',
sqls int(1) default 0 comment '获取sql注入',
create_time timestamp DEFAULT CURRENT_TIMESTAMP
)charset =utf8mb4;
alter table Sec_Links_0 add unique(url);
create table if not exists Sec_Links_1(
id int primary key auto_increment,
url varchar(100) comment '记住,这里是按照深度分类,数量较小',
links longtext comment '(一个列表,其中保存动态超链接)',
sqls int(1) default 0 comment '(扫描SQL注入,状态:0/1)',
xss int(1) default 0 comment '(扫描xss,状态:0/1)',
urls int(1) default 0 comment '(扫描url跳转,状态:0/1)',
lfi int(1) default 0 comment '(扫描文件包含,文件读取,状态:0/1)',
rce int(1) default 0 comment '(扫描命令执行,状态:0/1)',
create_time timestamp DEFAULT CURRENT_TIMESTAMP
)charset =utf8mb4;
alter table Sec_Links_1 add unique(url);
create table if not exists Sec_Links_2(
id int primary key auto_increment,
url varchar(100)comment '记住,这里是按照路径相似度分类,数量较大',
links longtext comment '(一个列表,其中保存动态超链接)',
sqls int(1) default 0 comment '(扫描SQL注入,状态:0/1)',
xss int(1) default 0 comment '(扫描xss,状态:0/1)',
urls int(1) default 0 comment '(扫描url跳转,状态:0/1)',
lfi int(1) default 0 comment '(扫描文件包含,文件读取,状态:0/1)',
rce int(1) default 0 comment '(扫描命令执行,状态:0/1)',
create_time timestamp DEFAULT CURRENT_TIMESTAMP
)charset =utf8mb4;
alter table Sec_Links_2 add unique(url);
create table if not exists Sec_R_links(
id int primary key auto_increment,
url varchar(100),
links longtext comment '(一个字典,其中保存按照命令执行漏洞类型的url链接,比如action,do,jsp,php等)',
rce int(1) default 0 comment '(扫描命令执行,状态:0/1)',
ssf int(1) default 0 comment '(扫描ssrf,状态:0/1)',
create_time timestamp DEFAULT CURRENT_TIMESTAMP
)charset =utf8mb4;
alter table Sec_R_links add unique(url);
create table if not exists Sec_success(
id int primary key auto_increment,
url varchar(100),
vlun_type longtext comment '保存成功状态',
create_time timestamp DEFAULT CURRENT_TIMESTAMP
)charset =utf8mb4;
create table if not exists Sec_Ip_Vluns(
id int primary key auto_increment,
url varchar(100),
ip varchar(16),
unau_get int(1) default 0 comment '获取未授权访问',
wpas_get int(1) default 0 comment '获取弱口令',
port_get int(1) default 0 comment '获取开放端口的信息',
other_vlun int(1) default 0 comment '获取其他类型漏洞',
create_time timestamp DEFAULT CURRENT_TIMESTAMP
)charset =utf8mb4;
alter table Sec_Ip_Vluns add unique(ip);
create table if not exists Sec_Urls(
id int primary key auto_increment,
url varchar(80) COMMENT '所有爬行的网页中的链接保存一下,这个功能由子域名爆破的web模块实现',
title varchar (80) comment '网页标题',
power varchar (80) comment '网址使用脚本语言',
server varchar (80) comment '网址服务器类型',
content longtext comment '网页内容,到时候可以做URL采集判断',
create_time timestamp DEFAULT CURRENT_TIMESTAMP
)charset =utf8mb4;
alter table Sec_Urls add unique(url);
create table if not exists Sec_Fail_Links(
id int primary key auto_increment,
url varchar(80) COMMENT '所有爬行的网页中的链接访问失败的保存一下',
get_links int(1) default 0 comment '如果需要再次使用,可以做判断',
create_time timestamp DEFAULT CURRENT_TIMESTAMP
)charset =utf8mb4;
alter table Sec_Fail_Links add unique(url);
文件详情
注:勿删文件夹或者修改文件名
在 Modules 文件夹下的不同文本文件功能:
domains.txt
保存需要监控的子域名资产,格式如下:
jd.com
baidu.com
qq.com
iqiyi.com
....
rar.txt
保存的扫描备份文件字典
Sub_Big_Dict.txt
爆破二级域名字典
Sub_Sma_Dict.txt
爆破三级域名字典
default.docx
自动化生成报表模板
geckodriver.exe
FireFox驱动
result
存储扫描结果报表文件夹,勿删
_py2.py
检测Python2环境
black_list
存储网址爬行黑名单,其下的网址不会保存到数据库中
误报问题
- 当扫描目标数量低于线程数*2时,不会开启扫描,所以尽量多导入网址
- SQL注入使用SQLMAP提供sql注入检测功能,但是也存在误报,误报率在20%
- XSS检测误报率在10%左右
- COSR劫持危害性比较小,基本上都不开启扫描功能
- 关于文件读取基本上都存在误报,不要开启
- 总的来说,能玩的地方只有子域名监控,git/svn源码泄露扫描,备份文件泄露扫描,xss,sql,url跳转。
超链接爬行问题
一共实现了三种方案:
- 使用requests简单模拟爬虫方式,获取网页下所有的目录和链接,许多通过js生成的数据是获取不到。但是节省资源。
- 使用selenium操作浏览器,实现自动网页滑动,点击,随后通过mitmproxy中间件获取到所有的URL请求,优点是几乎能抓所有链接和ajax请求,但是消耗资源太大,故本版本移除该功能。
- 使用pyppeteer对网页自动化操作,然后获取所有的数据请求,和第二点一样,消耗资源太大,故本版本移除该功能。
考虑到以后,提供配置功能,可以选择超链接爬行方式。
稳定可用持续性
- 在运行环境检测中,使用selenium驱动打开网页,但是网页可能有时候不能打开。这一点可以通过修改host文件破解
- URL跳转漏洞,跳转到的目标网站有时候可能会宕机,无法正确检测到结果。
- 其他2020年可用性未知。
应用限制
- 无法提供对GOV&EDU扫描功能
- 低配主机可能无法正常运行,解决方案也很简单,降低线程数,关闭不必要不需要的扫描功能即可。
- 在CPU使用率到达100%,可能会导致部分扫描功能子模块无法启动,弹窗警告。
补充
虽然不能让你在SRC称王称霸,但是在补天一个礼拜换一换桶泡面还是可以的。
试验注册一个新的账号,挂了5天,补天刷到1200名,虽然都是体力活,但是kb还是很香的。当然电费和物理机的负载也是很香的。
任何用扫描器,自动化漏洞挖掘工具找到的漏洞,质量都不会太高,对技术提升也没有太大的作用。但是如果能根据现有的漏洞基础上,加大漏洞的威胁性,比如你扫到了备份,那么可以从中找数据库配置或者备份信息,以及一些登陆的敏感密码然后对代码做审计。对已知漏洞进行组合进一步拓展漏洞的危害,才是SRC中漏扫的意义。
目前版本为0.97版本,还有许多主机,数据库,服务类的漏洞都没有补充完善,漏扫的规则也不是特别满意。完整的后台管理可数据可视化虽然提上日程,但是还在设计阶段。对应漏扫报表的地方,还需要进一步的美化完善。
最后希望大家不要执着于排名与漏洞的数量,应该花费更多的时间去提升漏洞的质量水平,提高自己的技术水准。
声明
本软件只做初步探测,无攻击性行为。请使用者遵守《中华人民共和国网络安全法》,勿用于非授权的测试,检测目标仅限于各大SRC,补天SRC,公益SRC进行测试。
本来三个月前就放在GITHUB提供使用,然后由于某些人修改注入进程进行恶意扫描,然后被网警警告,更有甚者挂在咸鱼论坛出售,WTF???,于是停止开放下载,当初为了防止这种类似的事发生,所以在每个模块都加了14个操作开关,即访问我的github,csdn等网站,只要其中一个网站出现操作开关的关键词就停止扫描……..

